
MongoDB vs PostgreSQL: 15 krytycznych różnic
Opublikowany: 2022-06-15Rozpoczynając nowy projekt, jedną z rzeczy, z którymi deweloperzy mogą się zmagać, jest wybór stosu. Skupienie się na właściwej technologii w celu rozwiązania problemu może być denerwującym doświadczeniem. W szczególności bazy danych mogą być trudne do ustalenia, zwłaszcza jeśli nie masz pewności, w jaki sposób będą wykorzystywane Twoje dane.
Ponieważ bazy danych są podstawową podstawą tworzenia oprogramowania i służą różnym celom do tworzenia projektów wszelkiego rodzaju i rozmiarów, pomaga zrozumieć znaczenie baz danych w wyborze odpowiedniej struktury bazy danych dla stosu.
Ten artykuł pomoże Ci wybrać odpowiednią bazę danych typu open source, badając różnice między dwoma świetnymi systemami zarządzania bazami danych: MongoDB i PostgreSQL.
Co to jest MongoDB?

MongoDB to wieloplatformowa, nierelacyjna baza danych typu open source, opublikowana 11 lutego 2009 r. Jest znana z używania dokumentów podobnych do JSON z opcjonalnymi schematami.
MongoDB jest uważana za jedną z najbardziej zaawansowanych na rynku usług baz danych w chmurze z niezrównaną mobilnością i dystrybucją danych w Azure, AWS i Google Cloud, wbudowaną automatyzacją do optymalizacji obciążenia i zasobów.
Umożliwia również utworzenie bazy danych w chmurze w ciągu kilku minut przy użyciu interfejsu Atlas CLI, interfejsu użytkownika lub dostawcy zasobów infrastruktury jako usługi (IaaS).
Dzięki MongoDB Atlas możesz utrzymać działanie aplikacji, aby nadążyć za rosnącym ruchem, gdy nowe funkcje trafiają do Twojego potoku. MongoDB Atlas zapewnia swoim użytkownikom zaawansowane narzędzia do optymalizacji baz danych, dzięki czemu zawsze dysponujesz zasobami bazy danych, których potrzebujesz do dalszego budowania.
Główne cechy
Oto kilka kluczowych cech MongoDB, które zapewniają mu miejsce wśród najlepszych nierelacyjnych baz danych na rynku:
- Porady dotyczące wydajności : W miarę rozwoju aplikacji MongoDB pomaga w opracowywaniu najlepszych praktyk projektowania schematów na żądanie w celu uzyskania maksymalnej wydajności.
- Klastry wielochmurowe : dzięki MongoDB możesz włączyć odporne i wydajne aplikacje, które wykorzystują dwie lub więcej chmur jednocześnie.
- Równoważenie obciążenia : MongoDB ułatwia kontrolę współbieżności w celu obsługi wielu żądań klientów równolegle do innych serwerów. Może to pomóc w zmniejszeniu obciążenia każdego serwera, zapewniając jednocześnie spójność danych i czas pracy bez przestojów, a także umożliwia stosowanie skalowalnych aplikacji.
Przypadków użycia
MongoDB jest używany przez tysiące organizacji na całym świecie do przechowywania danych lub jako usługa bazy danych aplikacji.
MongoDB odgrywa kluczową rolę w:
- Zarządzanie treścią : dzięki MongoDB możesz udostępniać i przechowywać dowolny rodzaj treści, konstruować dowolne funkcje i wplatać dowolne dane w ramach jednej bazy danych. MongoDB zapewni Ci sukces dzięki standardowemu sprzętowi i bardziej produktywnym zespołom, aby Twój projekt kosztował 10% tego, co powinien, oferując jednocześnie wszystkie funkcje potrzebne do tworzenia aplikacji bogatych w treść.
- Płatności : jeśli opracowujesz nowy produkt płatniczy, elastyczność danych MongoDB pozwoli temu nowemu produktowi szybko dotrzeć na rynek, bez konieczności martwienia się o niepotrzebną złożoność, taką jak fragmentacja danych. Nawet jeśli kierujesz dojrzałym przedsiębiorstwem, które próbuje zmodernizować swój ekosystem płatności, możesz wykorzystać elastyczność MongoDB, aby wykorzystać go jako skonsolidowaną warstwę danych operacyjnych, umożliwiając tworzenie nowych produktów i usług przy użyciu istniejących danych bez ryzykownego rozwiązania do obcinania plików cookie.
- Personalizacja : MongoDB umożliwia personalizację doświadczeń milionów klientów w czasie rzeczywistym dzięki funkcjom takim jak ukierunkowane oferty, dostosowane strony główne i logowanie do sieci społecznościowych. Możesz nawet uruchamiać złożone zapytania bezpośrednio na swoich danych, nie martwiąc się o przekształcanie, wyodrębnianie i ładowanie.
- Odciążanie komputera mainframe : za pomocą MongoDB możesz łatwo przenieść obciążenia z komputera mainframe. Odciążanie komputerów mainframe to proces replikowania powszechnie dostępnych danych z komputerów mainframe do warstwy danych operacyjnych (ODL) zbudowanej na bazie MongoDB, w stosunku do której można przekierowywać operacje z konsumujących aplikacji.
Co to jest PostgreSQL?

Pomimo popularności baz danych NoSQL, relacyjne bazy danych nadal są przydatne dla różnych aplikacji ze względu na ich niezawodność i silne możliwości zapytań.
Relacyjne bazy danych doskonale nadają się do uruchamiania złożonych zapytań i raportowania opartego na danych w przypadkach, gdy struktura danych nie zmienia się często. Bazy danych typu open source, takie jak PostgreSQL, oferują opłacalną alternatywę jako stabilna baza danych klasy produkcyjnej w porównaniu do licencjonowanych współczesnych, takich jak SQL Server i Oracle.
PostgreSQL to wysoce stabilny system zarządzania bazą danych, wspierany przez ponad 20 lat rozwoju społeczności, który doprowadził do jego wysokiego poziomu integralności, odporności i poprawności. Możesz używać PostgreSQL jako głównego magazynu danych lub źródła danych dla różnych aplikacji mobilnych, geoprzestrzennych, analitycznych i internetowych.
PostgreSQL nie wiąże się również z kosztami licencji, eliminując ryzyko nadmiernego wdrożenia. Jego oddana grupa entuzjastów i współpracowników regularnie znajduje błędy i rozwiązania, przyczyniając się do ogólnego bezpieczeństwa systemu baz danych.
Główne cechy
Oto kilka istotnych cech PostgreSQL, które sprawiają, że jest to jedna z najczęściej używanych obecnie baz danych:
- Kolumny nieatomowe : jednym z podstawowych ograniczeń modelu relacyjnego jest to, że kolumny muszą być niepodzielne. PostgreSQL nie ma jednak tego ograniczenia i pozwala kolumnom mieć podwartości, do których zapytania mają łatwy dostęp.
- Obsługa danych JSON : Możliwość wykonywania zapytań i przechowywania danych JSON umożliwia PostgreSQL również uruchamianie obciążeń NoSQL — powiedzmy, jeśli projektujesz bazę danych do przechowywania danych z wielu czujników i nie masz pewności, które kolumny będą potrzebne do obsługi wszelkiego rodzaju czujników. W tym scenariuszu można skonstruować tabelę tak, aby jedna z kolumn była w formacie JSON do przechowywania ciągle zmieniających się lub nieustrukturyzowanych danych.
- Funkcje okien: funkcje okien PostgreSQL odgrywają integralną rolę w czynieniu ich ulubionymi aplikacjami analitycznymi. Za pomocą funkcji Window można wykonywać funkcje obejmujące wiele wierszy i zwracać tę samą liczbę wierszy. Funkcje okna różnią się od funkcji agregujących w tym sensie, że po agregacji funkcje agregujące mogą zwracać tylko jeden wiersz.
Przypadków użycia
Oto kilka przypadków użycia, w których PostgreSQL przydaje się:
- Sfederowana baza danych koncentratora : obsługa JSON PostgreSQL i zewnętrzne opakowania danych pozwalają mu łączyć się z innymi magazynami danych — w tym z typami NoSQL — i służyć jako sfederowany koncentrator dla wielojęzycznych systemów baz danych.
- Dane naukowe : Projekty naukowe i badawcze mogą generować terabajty danych, którymi należy zarządzać w sposób najbardziej efektywny i korzystny. PostgreSQL oferuje wspaniały silnik SQL z rozbudowanymi możliwościami analitycznymi, co sprawia, że przetwarzanie dużych ilości danych to bułka z masłem.
- Produkcja : Różni światowej klasy producenci przemysłowi wykorzystują PostgreSQL do przyspieszenia innowacji i rozwoju poprzez procesy zorientowane na klienta, przy jednoczesnej optymalizacji wydajności łańcucha dostaw poprzez wykorzystanie PostgreSQL jako zaplecza pamięci masowej.
- Stos open source LAPP : PostgreSQL może uruchamiać dynamiczne aplikacje i strony internetowe jako część solidnej alternatywy dla stosu LAMP. LAPP to skrót od Linux, Apache, PostgreSQL, Python, PHP i Perl.
MongoDB vs PostgreSQL: bezpośrednie porównanie
Prawdziwym pytaniem nie jest MongoDB vs PostgreSQL, ale raczej najlepsza baza dokumentów vs najlepsza relacyjna baza danych.
Dość często, na początku projektu deweloperskiego, liderzy projektów dobrze rozumieją przypadek użycia, ale nie mają jasności co do konkretnych funkcji aplikacji, których potrzebowaliby ich użytkownicy i biznes. W końcu muszą postawić na wybór i mają nadzieję, że najlepiej pasuje.
W następnej sekcji wyjaśnimy różnice między MongoDB i PostgreSQL, aby ułatwić Ci podjęcie tej decyzji. Nasze informacje opierają się na kluczowych czynnikach, takich jak architektura, zgodność z ACID, rozszerzalność, replikacja, bezpieczeństwo i wsparcie, aby wymienić tylko kilka.
Zanurzmy się!
Zgodność z kwasem
Jedną z najważniejszych cech relacyjnych baz danych, które ułatwiają pisanie aplikacji, są transakcje ACID. Jeśli chodzi o poziomy izolacji w transakcjach bazy danych, PostgreSQL domyślnie używa odczytanego poziomu izolacji zatwierdzonego. Umożliwia także użytkownikom dostrojenie odczytu zatwierdzonego poziomu izolacji do poziomu izolacji możliwego do serializacji.
Należy tutaj zauważyć, że transakcje umożliwiają wprowadzanie lub wycofywanie różnych zmian w bazie danych w grupie. Dlatego w relacyjnej bazie danych dane byłyby modelowane w niezależnych tabelach nadrzędny-podrzędny w schemacie tabelarycznym.
Dla porównania, bazy danych dokumentów mają łatwiejszy czas na wykonywanie transakcji, ponieważ gromadzą dane w dokumencie, a ponieważ odczyt i zapis jest operacją niepodzielną, nie wymaga transakcji wielodokumentowej.
MongoDB obsługuje pełną izolację podczas aktualizacji dokumentu. Wszelkie błędy spowodowałyby wycofanie operacji aktualizacji, cofnięcie zmiany i zapewnienie klientom spójnego widoku dokumentu.
MongoDB obsługuje również transakcje bazy danych w wielu dokumentach, umożliwiając wycofanie lub zatwierdzenie fragmentów powiązanych zmian jako grupy. Dzięki możliwości transakcji wielodokumentowych MongoDB jest jedną z nielicznych baz danych, która łączy elastyczność, szybkość i moc modelu dokumentów z gwarancjami ACID tradycyjnych baz danych.
Architektura/Model dokumentu
Model dokumentu MongoDB pozwala użytkownikowi w naturalny sposób odwzorować obiekty w kodzie aplikacji, ułatwiając programistom z pełnym stosem naukę i używanie. Dokumenty umożliwiają łatwe przedstawianie hierarchicznych relacji w celu przechowywania tablic i innych, bardziej wyrafinowanych struktur.
Dzięki przechowywaniu danych w polach, takich jak zagnieżdżone dokumenty podrzędne i tablice, powiązane informacje w dokumentach JSON można przechowywać razem, aby uzyskać szybki dostęp do zapytań za pośrednictwem języka zapytań MongoDB.
Dzięki MongoDB możesz przechowywać dane jako dokumenty w reprezentacji binarnej znanej jako binarny JSON (BSON). Pola mogą się różnić w zależności od dokumentu, który obsługuje, dlatego nie ma potrzeby deklarowania struktury dokumentów do systemu — dokumenty są samoopisujące.
Jeśli musisz dodać nowe pole do dokumentu, to pole można wygenerować bez wpływu na inne dokumenty w kolekcji lub aktualizowania ORM lub centralnego katalogu systemowego.
MongoDB zapewnia również opcję sprawdzania poprawności schematu w celu wymuszenia kontroli zarządzania danymi w każdej kolekcji. Ta elastyczność przydaje się podczas zestawiania informacji z wielu różnych źródeł lub wprowadzania zmian w dokumentach w czasie, zwłaszcza gdy nowa funkcjonalność aplikacji jest konsekwentnie wdrażana.
PostgreSQL zawiera model architektury klient-serwer, który składa się z następujących dwóch procesów:
- Proces po stronie klienta : są to aplikacje wykorzystywane przez użytkowników do interakcji z bazą danych. Zwykle ma prosty interfejs użytkownika i służy do komunikacji między użytkownikiem a bazą danych za pośrednictwem interfejsów API.
- Proces po stronie serwera : jest to aplikacja „Postgres”, która zajmuje się operacjami, połączeniami oraz zasobami dynamicznymi i statycznymi. Działająca witryna PostgreSQL jest obsługiwana przez Postmaster, centralny proces koordynujący. Demon Postmaster jest odpowiedzialny za:
- Wykonywanie odzyskiwania
- Inicjalizacja serwera
- Wyłączanie serwera
- Uruchamianie procesów w tle
- Zarządzanie żądaniami połączeń od nowych klientów
.
Rozciągliwość
Rozszerzalność to po prostu jakość zaprojektowania, aby umożliwić dodawanie nowych możliwości lub funkcjonalności.
PostgreSQL obsługuje rozszerzalność na kilka sposobów, w tym funkcje i procedury składowane. To, co sprawia, że PostgreSQL jest tak rozbudowany, to operacje oparte na katalogach.
Relacyjne bazy danych często przechowują informacje o tabelach, bazach danych, kolumnach itp. w katalogach systemowych. Te „słowniki danych” są widoczne dla użytkownika jako tabele, ale zawierają informacje przechowywane wewnętrznie przez system bazy danych.
PostgreSQL przechowuje informacje o kolumnach i tabelach wraz z informacjami o typach danych, funkcjach i metodach dostępu.
Co więcej: PostgreSQL może również zawierać w sobie kod napisany przez użytkownika poprzez dynamiczne ładowanie. Często użytkownicy mogą wymagać określonej funkcjonalności, którą można wdrożyć za pośrednictwem bibliotek współdzielonych. Użytkownicy mogą po prostu określić plik kodu, a PostgreSQL załaduje go zgodnie z wymaganiami, dzięki czemu będzie on wyjątkowo dostosowany do szybkiego prototypowania nowych aplikacji.
Z drugiej strony MongoDB w końcu stało się rozszerzalne, umożliwiając użytkownikom tworzenie własnych funkcji i korzystanie z nich w ramach. Jest to odpowiednik funkcji zdefiniowanych przez użytkownika (UDF), które umożliwiają użytkownikom relacyjnych baz danych (takich jak PostgreSQL) rozszerzanie instrukcji SQL.
Co więcej, zarówno PostgreSQL, jak i MongoDB obsługują kilka rozszerzeń i wtyczek, takich jak Adminer do zarządzania bazą danych.
Współpraca i sprawność
MongoDB ma model dokumentów, dzięki czemu współpraca i rozwój są łatwiejsze i szybsze do wdrożenia. MongoDB zasadniczo używa JSON lub BSON do przechowywania swoich danych jako dokumentów.
BSON zawiera kilka typów danych nieobecnych w danych JSON, takich jak DateTime , long , int i byte array, które pomagają efektywniej obsługiwać dane, ponieważ byłyby bardziej szczegółowe w zależności od typu danych, zamiast obsługiwać wszystko jak uniwersalny typ „liczby”. Sprawia, że zapytania są wykonywane szybciej, ponieważ są one w formacie serializacji, który skutecznie archiwizuje dokumenty w formacie JSON.
BSON pomija klucze, które nie są przydatne w zapytaniu, dzięki czemu pobieranie danych jest szybsze. Użytkownik może dokładniej zdefiniować strukturę dokumentu i podjąć pewne prace rozwojowe, wprowadzając nowe pola, przerabiając dane lub rozwijając go, gdy uzna to za stosowne.
Ta elastyczność jest ogromną zaletą dla MongoDB, ponieważ pomaga uniknąć opóźnień spowodowanych zwróceniem się do administratora o zmianę struktury instrukcji języka definicji danych, a następnie rozpoczęcie od zera przez ponowne utworzenie lub ponowne załadowanie bazy danych.
MongoDB ułatwia również współpracę między programistami lub zespołami, dzięki czemu nie ma potrzeby pośrednictwa ani skomplikowanej komunikacji między zespołami.
Jeśli chodzi o współpracę, PostgreSQL obejmuje uprawnienia na poziomie użytkownika, dziedziczenie ról i uprawnienia na poziomie tabeli. Możesz zarządzać użytkownikami i nadawać im uprawnienia do odczytu i zapisu.
Co więcej, możesz również przeglądać różne grupy lub działania dostępu do danych użytkowników za pomocą opcji audytu, która zapewnia dodatkową warstwę bezpieczeństwa. Jednak PostgreSQL nie jest tak szybki jak MongoDB, ponieważ jest relacyjną bazą danych przechowującą dane w wierszach i kolumnach.
Obsługa kluczy obcych
Kluczową cechą odróżniającą MongoDB od PostgreSQL jest podejście do przechowywania danych.
Ponieważ nie jest to relacyjne, MongoDB używa kolekcji zamiast tabel. Klucz obcy to po prostu zestaw atrybutów w tabeli, który odwołuje się do klucza podstawowego innej tabeli. Klucz obcy łączy te dwie tabele ze sobą.
Ponieważ w MongoDB nie ma tabel, nie ma też kluczy obcych w MongoDB; stąd brak ograniczeń związanych z kluczem obcym. Jednak MongoDB ma standard DBRef, który pomaga ujednolicić tworzenie referencji.
Z drugiej strony PostgreSQL obsługuje klucze obce, ponieważ jest zgodny z SQL. Włączając ograniczenia klucza obcego, PostgreSQL może zatrzymać wstawianie nieprawidłowych danych do kolumn kluczy obcych.
Partycjonowanie i fragmentowanie
Partycjonowanie i sharding polegają zasadniczo na podzieleniu dużych zestawów danych na mniejsze podzbiory. Dzielenie na fragmenty oznacza, że dane są przechowywane na wielu komputerach podczas partycjonowania grup tych danych w ramach jednej instancji bazy danych.

MongoDB jest skalowalny dzięki partycjonowaniu danych między instancjami w ramach klastra. Nie dzieli dokumentów na części, ponieważ są to niezależne jednostki, co ułatwia ich dystrybucję na różnych serwerach, podczas gdy dane są zachowywane lokalnie.
Dane mogą być z łatwością dystrybuowane w różnych regionach za pośrednictwem usługi chmurowej MongoDB Atlas. Możesz również zdecydować się na ciągłe przechowywanie ich w określonych regionach lub regionach globalnych, aby zapewnić skrócenie czasu oczekiwania.
Od wersji 5.0 MongoDB zawiera funkcję reshardingu „na żywo”, która zapewnia znaczną oszczędność czasu, ponieważ wystarczy ustawić politykę. Baza danych może automatycznie redystrybuować dane, gdy nadejdzie czas.
Wcześniej można było to zrobić bez wyłączania systemu, ale proces był skomplikowany i ryzykowny. Chociaż MongoDB przez jakiś czas posiadało globalne geo-partycjonowanie, dane rosły w różnych krajach w różnym tempie. Reharding na żywo może być korzystny w przypadku danych, które muszą pozostać lokalne w danym kraju.
Z drugiej strony PostgreSQL obsługuje deklaratywne partycjonowanie, które jest zasadniczo sposobem na określenie sposobu podziału tabeli na partycje. Dzielona tabela nazywana jest tabelą partycjonowaną, specyfikacja obejmuje metodę partycjonowania, a lista kolumn lub wyrażeń, które mają zostać użyte, nazywana jest kluczem partycji.
Można zaimplementować partycjonowanie za pomocą zakresu, w którym tabelę można podzielić według zakresów zdefiniowanych przez kolumnę klucza lub zestaw kolumn, bez nakładania się zakresów wartości przypisanych do różnych partycji.
Można również zaimplementować partycjonowanie listy, w którym tabela jest podzielona na partycje zgodnie z określonymi wartościami klucza.
Replikacja
Replikacja to proces tworzenia kopii tego samego zestawu danych na więcej niż jednym serwerze. Umożliwia administratorom baz danych zapewnienie wysokiej redundancji danych i wysokiej dostępności danych.
W przypadku MongoDB osiąga się to za pomocą „zestawu replik” — zsynchronizowanego klastra składającego się z trzech lub więcej serwerów, które replikują dane między sobą. Zapewnia to redundancję i ochronę przed wszelkimi przestojami, które mogą wystąpić w przypadku zaplanowanej przerwy na konserwację lub awarii systemu, zwiększając w ten sposób odporność bazy danych na błędy.
Zestawy replik można również wdrażać w różnych centrach danych, ponieważ przydają się w przypadku awarii regionalnych. Można to zrobić za pomocą MongoDB Atlas, dzięki czemu budowanie i konfigurowanie tych klastrów jest prostsze i szybsze.
PostgreSQL oferuje replikację podstawowa-wtórna. Dzienniki zapisu z wyprzedzeniem umożliwiają udostępnianie zmian dokonanych w węzłach replik, dzięki czemu możliwa jest replikacja asynchroniczna. Inne rodzaje replikacji obejmują replikację logiczną, replikację strumieniową i replikację fizyczną.
Indeksy
Indeksy to obiekty lub struktury, które pozwalają nam szybciej pobrać określone wiersze lub dane.
PostgreSQL dostarcza szereg unikalnych typów indeksów, które efektywnie dopasowują się do każdego obciążenia zapytania. Jego techniki indeksowania obejmują B-drzewo, wielokolumnowe i wyrażenia. Ponadto w PostgreSQL można również zaimplementować częściowe i zaawansowane techniki indeksowania, takie jak GiST, KNN Gist, SP-Gist, GIN, BRIN, obejmujące indeksy i filtry bloom.
Z drugiej strony MongoDB umożliwia przechowywanie danych w dowolnej strukturze, do której można szybko uzyskać dostęp poprzez indeksowanie, bez względu na to, jak głęboko są zagnieżdżone w tablicach lub poddokumentach.
Język i składnia
Zarówno MongoDB, jak i PostgreSQL obsługują różne języki.
MongoDB zapewnia obsługę sterowników dla niektórych z najlepszych języków baz danych, takich jak Python, R, Java, Scala, C, C++, C#, Node.js i wielu innych. Te biblioteki i sterowniki MongoDB obsługują wszystkie funkcje MongoDB, zapewniając wysoką wydajność i skalowalność we wszystkich aplikacjach.
PostgreSQL obsługuje kilka języków proceduralnych z podstawową dystrybucją, taką jak PL/pgSQL, PL/Python, PL/Perl i PL/Tcl wraz z innymi językami opracowanymi i utrzymywanymi poza podstawową dystrybucją PostgreSQL, takimi jak PL/Java, PL/PHP i PL/ Rubin.
Normalizacja
Normalizacja to proces konstruowania relacyjnej bazy danych w celu zmniejszenia nadmiarowości danych, zminimalizowania anomalii w modyfikacji danych i poprawy integralności danych.
MongoDB może obsługiwać zarówno znormalizowane, jak i zdenormalizowane modele danych (znane również jako modele osadzone).
Modele osadzone umożliwiają aplikacjom przechowywanie powiązanych informacji w tym samym rekordzie bazy danych, co zapewnia lepszą wydajność operacji odczytu i możliwość pobierania powiązanych danych w ramach pojedynczej operacji bazy danych.
Ponadto można również aktualizować powiązane dane w pojedynczej operacji zapisu atomowego, podczas gdy aplikacje wykonują mniej zapytań w celu wykonania typowych operacji. Dokumenty w MongoDB dla osadzonego modelu danych muszą być mniejsze niż maksymalny rozmiar dokumentu BSON (16 MB).
Znormalizowane modele danych opisują relacje za pomocą odwołań między dokumentami. Byłoby to korzystne, gdy osadzanie może skutkować powielaniem danych, ale niewystarczająca wydajność odczytu przeważa nad konsekwencjami duplikacji.
Jednak proces denormalizacji zwykle powoduje duże zużycie pamięci, gdy wcześniej znormalizowane dane w bazie danych są grupowane w celu zwiększenia wydajności.
Schematy PostgreSQL mają zidentyfikowaną relację. Strukturę można zidentyfikować za pomocą relacji 1:1, 1:wiele lub wiele:1. Normalizacja danych może być bardzo korzystna, ponieważ usuwa zbędne kopie danych, zapewniając w ten sposób również integralność.
Wydajność
Ocena wydajności dwóch różnych systemów baz danych jest wyzwaniem, ponieważ zarówno MongoDB, jak i PostgreSQL mają różne sposoby przechowywania i pobierania danych.
MongoDB został zbudowany w celu skalowania w poziomie, ponieważ często łączy swoją moc z dodatkowymi maszynami i nie polega na mocy obliczeniowej. Jest w stanie zasilać ogromne aplikacje, niezależnie od tego, czy jest mierzony rozmiarami danych czy użytkownikami.
MongoDB może również obsługiwać przypadki użycia, które wymagają szybkiego wykonywania zapytań i mogą obsługiwać duże ilości danych. Może obejmować łącznie setki maszyn.
Od MongoDB 4.4 zapytania zaimplementowane w zestawach replik zapewniają lepszą i przewidywalną wydajność dzięki odczytom „zabezpieczonym”. Te odczyty są kierowane do wielu węzłów w zestawie replik, dopóki najszybszy węzeł nie odpowie.
PostgreSQL, choć nie tak szybki jak MongoDB pod względem szybkości wstawiania, wyróżnia się pod względem zgodności z ACID. Transakcje są przetwarzane bezpiecznie i niezawodnie, co pozwala na niepowodzenie całej transakcji zamiast wykonania zapisu, który częściowo się powiódł.
MongoDB dopiero niedawno (w wersji 4) zaczął obsługiwać transakcje ACID podobne do baz danych SQL.
W przeciwieństwie do MongoDB, PostgreSQL opiera się na strategii skalowania w górę (skalowanie w pionie) dla wolumenów danych i skalowania zapisów. Odbywa się to poprzez dodanie większej liczby zasobów sprzętowych, takich jak dyski, procesory i pamięć, do istniejącego węzła bazy danych.
Jednak PostgreSQL poczynił pewne wysiłki w kierunku optymalizacji wydajności, w tym dojrzałego planowania zapytań, kompilacji wyrażeń just-in-time (JIT), partycjonowania tabel i zrównoleglania zapytań odczytu.
Cena £
PostgreSQL jest całkowicie darmowy i open-source. Dzięki temu każdy może z łatwością korzystać z jego funkcji i wprowadzać modyfikacje w kodzie, gdy jest to konieczne.
MongoDB to również narzędzie typu open source. Jednak MongoDB ma inne opcje, takie jak Enterprise i Atlas (dla chmury), które mają różne ceny. Dla edycji MongoDB dla przedsiębiorstw oferowany jest lokalny model cenowy.
Mongo RealmDB jest dostępne bezpłatnie dla wszystkich użytkowników Atlas do oceny i lekkiego użytkowania, umożliwiając programistom tworzenie i publikowanie aplikacji mobilnych.
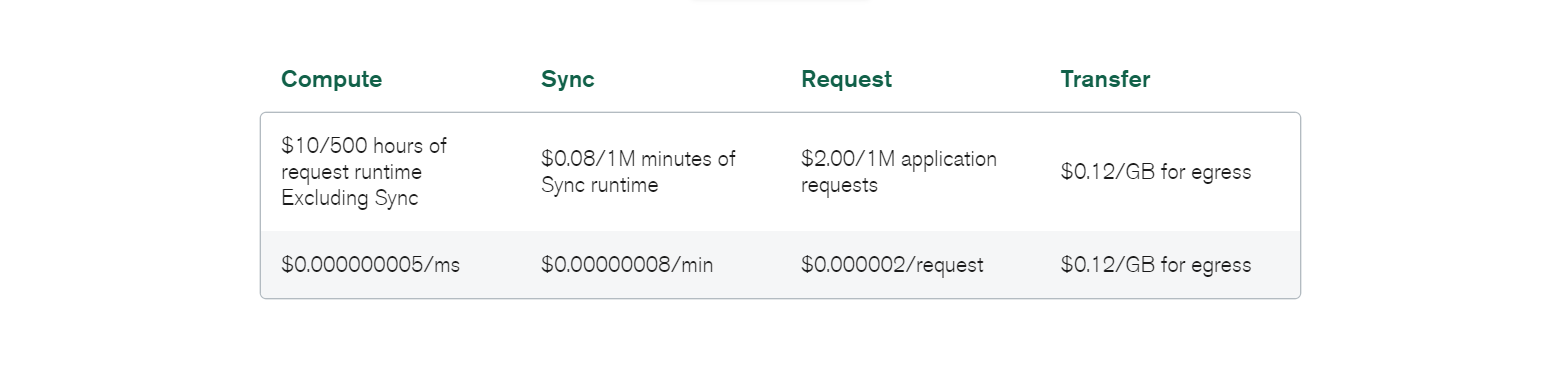
Migracja danych może również generować koszty ogólne; jest to jednak standard, niezależnie od bazy danych, którą zaimplementowałeś w swoim systemie.
Przetwarzanie zapytań
PostgreSQL wykorzystuje relacyjny model bazy danych, który polega na przechowywaniu danych w tabelach i wykorzystaniu strukturalnego języka zapytań (SQL) w celu uzyskania dostępu do bazy danych. Polecenia SQL można wprowadzać za pomocą terminala PostgreSQL psql . Posiada funkcję dużych obiektów, która zapewnia dostęp w stylu strumieniowym do danych użytkownika, które są przechowywane w specjalnej strukturze dużych obiektów.
Przed dodaniem danych należy zbudować schemat bazy danych, aby uzyskać jasne zrozumienie relacji danych w celu przetwarzania zapytań. Informacje pokrewne mogą być przechowywane w osobnych tabelach w bazie danych. Dostęp do tego można uzyskać za pomocą kluczy obcych i złączeń.
Dostosowanie struktury bazy danych po jej załadowaniu może być trudne. Potrzebuje kilku zespołów programistycznych, ops i administratora bazy danych, aby dokładnie koordynować zmiany wprowadzane w strukturze.
Z drugiej strony struktura danych MongoDB nie musi być planowana z wyprzedzeniem, ponieważ zasadniczo dotyczy danych nieustrukturyzowanych. Znacznie łatwiej jest też dostosować strukturę danych.
Deweloperzy mogą wybrać to, co najważniejsze w aplikacji i wprowadzić wymagane zmiany. MongoDB używa MQL, który może być używany do pracy z dokumentami w MongoDB i usuwania danych, zapewniając jednocześnie elastyczność i moc, jaką ma SQL.
MongoDB przetwarza dane jako dokumenty JSON. Możesz również wyszukiwać pola w dokumencie JSON. Dlatego MongoDB jest bardzo przydatny w przypadkach, gdy chcesz przechowywać dokumenty w elastycznym polu danych.
Podczas gdy PostgreSQL używa funkcji GROUP_BY do przetwarzania i uruchamiania zapytań agregujących, MongoDB zazwyczaj używa potoków agregacji do przetwarzania zapytań.
Jedną z głównych wad MongoDB jest to, że nie można łatwo dołączać do stołów. W PostgreSQL można to uprościć za pomocą instrukcji JOIN.
MongoDB próbował rozwiązać ten problem, wprowadzając wielowymiarowe typy danych, w których można osadzić jeden magazyn dokumentów w innym. Jest jednak zdezorganizowana i nie tak elegancka, jak prosta funkcja join , którą zawiera PostgreSQL.
Bezpieczeństwo
Jeśli chodzi o bezpieczeństwo, PostgreSQL przebija MongoDB. Ścisłe zasady rządzące strukturą bazy danych sprawiają, że PostgreSQL jest bardzo bezpieczną bazą danych, dzięki czemu może być niezawodny w użyciu w systemach bankowych.
PostgreSQL oferuje mnóstwo metod uwierzytelniania, w tym podłączany moduł uwierzytelniania (PAM) i lekki protokół dostępu do katalogu (LDAP), które zmniejszają powierzchnię ataku serwerów. Zapewnia również ochronę na poziomie serwera poprzez uwierzytelnianie oparte na hoście i uwierzytelnianie certyfikatów.
Ponadto PostgreSQL zapewnia szyfrowanie danych i umożliwia korzystanie z certyfikatów SSL podczas przesyłania danych przez sieć lub autostrady sieci publicznej. PostgreSQL umożliwia również opcjonalnie zaimplementowanie narzędzi do uwierzytelniania certyfikatów klienta (CCA) i używanie funkcji kryptogenicznych do przechowywania zaszyfrowanych danych w PostgreSQL.
Jednak poziom bezpieczeństwa PostgreSQL może się różnić w zależności od systemu chmurowego, nawet jeśli jest to ta sama baza danych.
MongoDB Atlas działa w ten sam sposób u trzech największych dostawców chmury, ułatwiając migrację między wieloma chmurami.
Ponadto MongoDB ma szyfrowanie po stronie klienta i na poziomie pola, co umożliwia użytkownikom szyfrowanie danych przed wysłaniem ich do bazy danych przez sieć. Ponieważ jednak dane są przechowywane w parach klucz-wartość w jednym rekordzie, brakuje im zabezpieczeń, którymi chwali się PostgreSQL; MongoDB skupia się na szybkości.
Wsparcie i społeczność
PostgreSQL jest całkowicie open-source i wspierany przez swoją społeczność, co wzmacnia go jako kompletny ekosystem. PostgreSQL często regularnie wydaje zaktualizowane wersje, a programiści, entuzjaści i firmy zewnętrzne zapewniają wsparcie i starają się rozwijać system, naprawiając błędy lub wprowadzając drobne modyfikacje w systemie bazodanowym.
Podobnie jak PostgreSQL, MongoDB posiada również forum społeczności, które umożliwia użytkownikom łączenie się z kilkoma innymi użytkownikami i uzyskiwanie odpowiedzi na ich ogólne pytania. Wsparcie dla przedsiębiorstw MongoDB może ponadto obejmować obszerną bazę wiedzy z przykładami użycia, szczegółowymi samouczkami, uwagami technicznymi dotyczącymi optymalizacji i najlepszymi praktykami.
Dodatkowo dostępne są bezpłatne kursy online ze szkoleniami i certyfikatami dostarczane przez MongoDB.
Wyzwania
Chociaż omówiliśmy cechy zarówno MongoDB, jak i PostgreSQL, które sprawiają, że są hitem wśród programistów, mają one również sporo słabości.
MongoDB skupia się na szybkim przetwarzaniu danych, ale brakuje mu bezpieczeństwa danych, które wydaje się posiadać PostgreSQL. Jest to dość wymagające w pamięci, ponieważ proces denormalizacji zwykle powoduje duże zużycie pamięci.
Dodatkowo, ponieważ nie ma obsługi złączeń, bazy danych MongoDB są nadmiernie dostarczane z danymi — czasami zduplikowanymi — przez co obciążają pamięć. MongoDB próbował również włączyć interpretację do innych języków zapytań jako część swojej rozszerzalności; może jednak spowolnić jego wydajność, ponieważ baza danych nie została początkowo zbudowana do obsługi relacyjnych modeli danych.
Tłumaczenie zapytań SQL na MongoDB może zająć dodatkowy czas na użycie silnika, co może opóźnić wdrożenie i rozwój.
Z drugiej strony, chociaż PostgreSQL jest łatwy w instalacji i można go dostosować do prawie wszystkich platform, jego wydajność może różnić się w zależności od platformy. Co więcej, nie posiada narzędzi rewizyjnych ani narzędzi raportowania, które mogłyby pokazać aktualny stan bazy danych. Być może będziesz musiał stale sprawdzać bazę danych, jeśli coś nie pójdzie zgodnie z planem, aby uniknąć zauważenia awarii, gdy jest za późno.
PostgreSQL jest również nieco wolniejszy, ponieważ koncentruje się na kompatybilności. Chociaż podjęto wysiłki, aby poprawić szybkość PostgreSQL, modyfikacje nadal wymagają trochę więcej pracy.
MongoDB vs PostgreSQL: co wybrać?
MongoDB jest nierelacyjną bazą danych, podczas gdy PostgreSQL jest relacyjną bazą danych. Podczas gdy bazy danych NoSQL pracują nad przechowywaniem danych w parach klucz-wartość jako jeden rekord, relacyjne bazy danych przechowują dane w różnych tabelach.
Jeśli priorytetem jest szybsza integracja danych i skalowalność na kilku serwerach, MongoDB może być odpowiednim wyborem dla Twojej firmy.
MongoDB może działać najlepiej po zintegrowaniu z platformą analityczną, ponieważ szybkość MongoDB zapewnia dynamiczną wydajność, która może pomóc śledzić zachowanie użytkownika w czasie rzeczywistym. Może być również bardzo korzystne dla Twojej firmy, jeśli posiadasz zapracowaną aplikację internetową, która nie jest zależna od schematu strukturalnego, takiego jak New York Times (który w rzeczywistości korzysta z MongoDB) lub katalogów produktów, w których potrzebujesz do przechowywania wielu obiektów z różnymi kolekcjami atrybutów.
Z drugiej strony PostgreSQL doskonale nadaje się do analizy danych i magazynowania. Jeśli tworzysz narzędzie do automatyzacji baz danych lub aplikację bankową, w których wolisz egzekwować bezpieczeństwo danych i gwarancje transakcyjne, PostgreSQL może być odpowiednim rozwiązaniem.
Streszczenie
Podsumowując, do tej pory omówiliśmy podstawowe szczegóły PostgreSQL i MongoDB. Omówiliśmy ich historię, kluczowe cechy i to, co je wyróżnia.
Chociaż zarówno PostgreSQL, jak i MongoDB tworzą niesamowite bazy danych, ostatecznie sprowadza się to do wyboru tego, co jest odpowiednie dla Twojej firmy.
Którą bazę danych między PostgreSQL i MongoDB wolisz? Daj nam znać w komentarzach!