
MongoDBとPostgreSQL:15の重要な違い
公開: 2022-06-15新しいプロジェクトを開始するとき、開発者が苦労する可能性のあることの1つは、スタックを選択することです。 問題を解決するために適切なテクノロジーに焦点を当てることは、神経を痛める経験になる可能性があります。 特にデータベースは、データがどのように使用されるかが不明な場合は特に、解決が難しい場合があります。
データベースはソフトウェア開発の基本的な基盤であり、あらゆるタイプとサイズのプロジェクトを構築するためのさまざまな目的に役立つため、データベースがスタックに適切なデータベース構造を選択することの重要性を理解するのに役立ちます。
この記事は、MongoDBとPostgreSQLという2つの優れたデータベース管理システムの違いを探ることで、適切なオープンソースデータベースを選択するのに役立ちます。
MongoDBとは何ですか?

MongoDBは、2009年2月11日にリリースされたクロスプラットフォームのオープンソースの非リレーショナルデータベースです。オプションのスキーマでJSONのようなドキュメントを使用することで知られています。
MongoDBは、Azure、AWS、Google Cloudにまたがる比類のないデータモビリティと分散、ワークロードとリソースの最適化のための組み込みの自動化を備えた、市場で最も先進的なクラウドデータベースサービスの1つと見なされています。
また、Atlas CLI、UI、またはIaaS(Infrastructure-as-a-Service)リソースプロバイダーを使用して、数分でクラウドデータベースを作成することもできます。
MongoDB Atlasを使用すると、アプリケーションを実行し続けて、新しい機能がパイプラインに導入されるときに急増するトラフィックに対応できます。 MongoDB Atlasは、ユーザーに高度なデータベース最適化ツールを提供するため、構築を続けるために必要なデータベースリソースを常に所有できます。
主な特徴
MongoDBのいくつかの重要な機能は、市場で最高の非リレーショナルデータベースの1つに数えられます。
- パフォーマンスに関するアドバイス:アプリケーションが進化するにつれて、MongoDBは、最高の効率を実現するためのオンデマンドスキーマ設計のベストプラクティスを支援します。
- マルチクラウドクラスター:MongoDBを使用すると、2つ以上のクラウドを同時に活用する復元力のある強力なアプリケーションを有効にできます。
- 負荷分散:MongoDBは、他のサーバーと並行して複数のクライアント要求を処理するための制御の同時実行を容易にします。 これにより、データの一貫性と稼働時間を確保しながら、すべてのサーバーの負荷を軽減し、スケーラブルなアプリケーションを実現できます。
ユースケース
MongoDBは、データストレージのニーズのために、またはアプリケーションのデータベースサービスとして、世界中の何千もの組織によって使用されています。
MongoDBは、次の点で極めて重要な役割を果たします。
- コンテンツ管理:MongoDBを使用すると、あらゆるタイプのコンテンツを提供および保存し、あらゆる機能を構築し、単一のデータベース内であらゆる種類のデータを織り込むことができます。 MongoDBは、コモディティハードウェアとより生産的なチームで成功するための準備を整え、コンテンツが豊富なアプリを構築するために必要なすべての機能を提供しながら、プロジェクトのコストを本来の10%にします。
- 支払い:新しい支払い製品を開発している場合、MongoDBのデータの俊敏性により、データの断片化などの不必要な複雑さを心配することなく、その新しい製品を迅速に市場に投入できます。 支払いエコシステムを最新化しようとしている成熟した企業をリードしている場合でも、MongoDBの柔軟性を活用して、統合された運用データレイヤーとして使用できるため、リスクの高いCookieカッターソリューションを使用せずに、既存のデータを使用して新しい製品やサービスを構築できます。
- パーソナライズ:MongoDBを使用すると、ターゲットを絞ったオファー、カスタマイズされたホームページ、ソーシャルメディアネットワークのサインオンなどの機能を使用して、何百万もの顧客のエクスペリエンスをリアルタイムでパーソナライズできます。 変換、抽出、読み込みを気にすることなく、データに対して直接複雑なクエリを実行することもできます。
- メインフレームのオフロード:MongoDBを使用すると、ワークロードをメインフレームから簡単に移動できます。 メインフレームのオフロードは、一般的にアクセスされるメインフレームデータをMongoDB上に構築された運用データレイヤー(ODL)に複製するプロセスであり、これに対して、消費するアプリケーションから操作をリダイレクトできます。
PostgreSQLとは何ですか?

NoSQLデータベースの人気にもかかわらず、リレーショナルデータベースは、その堅牢性と強力なクエリ機能により、さまざまなアプリケーションに関連し続けています。
リレーショナルデータベースは、データ構造が頻繁に変更されない場合に、複雑なクエリやデータベースのレポートを実行するのに最適です。 PostgreSQLのようなオープンソースデータベースは、SQL ServerやOracleのようなライセンスされた同時代のデータベースと比較して、安定した本番環境グレードのデータベースとして費用効果の高い代替手段を提供します。
PostgreSQLは非常に安定したデータベース管理システムであり、20年以上にわたるコミュニティ開発に支えられており、高レベルの整合性、回復力、および正確性をもたらしています。 PostgreSQLは、さまざまなモバイル、地理空間、分析、およびWebアプリケーションの主要なデータウェアハウスまたはデータソースとして使用できます。
PostgreSQLにはライセンス費用もかかりません。これにより、過剰な展開のリスクが排除されます。 熱心なファンと貢献者の専用グループは、定期的にバグと解決策を見つけ、データベースシステムの全体的なセキュリティを強化しています。
主な特徴
PostgreSQLのいくつかの顕著な機能により、今日最も広く使用されているデータベースの1つになっています。
- 非アトミック列:リレーショナルモデルの主な制約の1つは、列がアトミックである必要があることです。 ただし、PostgreSQLにはこの制約がなく、クエリが簡単にアクセスできるサブ値を列に含めることができます。
- JSONデータのサポート:JSONをクエリして保存する機能により、PostgreSQLはNoSQLワークロードも実行できます。たとえば、複数のセンサーからのデータを保存するデータベースを設計していて、必要な特定の列がわからない場合などです。あらゆる種類のセンサーをサポートします。 このシナリオでは、列の1つがJSONであるようなテーブルを作成して、継続的に変化するデータまたは非構造化データを格納できます。
- ウィンドウ関数:PostgreSQLウィンドウ関数は、分析アプリケーションのお気に入りにするために不可欠な役割を果たします。 ウィンドウ関数を使用すると、複数の行にまたがる関数を実行して、同じ数の行を返すことができます。 ウィンドウ関数は、集計関数が集計後に単一の行のみを返すことができるという意味で、集計関数とは異なります。
ユースケース
PostgreSQLが役立ついくつかのユースケースを次に示します。
- フェデレーションハブデータベース:PostgreSQLのJSONサポートと外部データラッパーにより、NoSQLタイプを含む他のデータストアと接続し、ポリグロットデータベースシステムのフェデレーションハブとして機能します。
- 科学データ:科学および研究プロジェクトはテラバイトのデータを生成する可能性があり、これらは最も効率的かつ有益に管理する必要があります。 PostgreSQLは、堅牢な分析機能を備えた素晴らしいSQLエンジンを提供します。これにより、大量のデータを簡単に処理できます。
- 製造業:さまざまな世界クラスの産業メーカーがPostgreSQLを活用して、PostgreSQLをストレージバックエンドとして使用することでサプライチェーンのパフォーマンスを最適化しながら、顧客中心のプロセスを通じてイノベーションを加速し、成長を推進しています。
- LAPPオープンソーススタック:PostgreSQLは、LAMPスタックの堅牢な代替手段の一部として動的なアプリとWebサイトを実行できます。 LAPPは、Linux、Apache、PostgreSQL、Python、PHP、およびPerlの略です。
MongoDBとPostgreSQL:直接比較
本当の問題は、MongoDBとPostgreSQLではなく、最高のドキュメントデータベースと最高のリレーショナルデータベースです。
多くの場合、開発プロジェクトの開始時に、プロジェクトリーダーはユースケースを十分に把握していますが、ユーザーやビジネスに必要な特定のアプリケーション機能について明確に把握していません。 彼らは結局、選択に賭けなければならず、それが最適であることを望んでいます。
次のセクションでは、MongoDBとPostgreSQLの違いを明らかにして、その決定を簡単に行えるようにします。 私たちの情報は、アーキテクチャ、ACIDコンプライアンス、拡張性、レプリケーション、セキュリティ、サポートなどの重要な要素に基づいています。
飛び込みましょう!
ACIDコンプライアンス
アプリケーションの作成を簡単にするリレーショナルデータベースの最も重要な機能の1つは、ACIDトランザクションです。 データベーストランザクション内の分離レベルに関する限り、PostgreSQLはデフォルトで読み取りコミット分離レベルを使用します。 また、ユーザーは読み取りコミットされた分離レベルをシリアル化可能な分離レベルまで調整できます。
ここで注意すべき重要な点は、トランザクションを使用すると、データベースにさまざまな変更を加えたり、グループでロールバックしたりできることです。 したがって、リレーショナルデータベースでは、データは表形式のスキーマ内の独立した親子テーブル全体でモデル化されます。
比較すると、ドキュメントデータベースは、ドキュメント内のデータを照合し、読み取りと書き込みが不可分操作であるため、複数のドキュメントトランザクションを必要としないため、トランザクションの実行が容易になります。
MongoDBは、ドキュメントの更新中の完全な分離をサポートしています。 エラーが発生すると、更新操作がトリガーされてロールバックされ、変更が元に戻され、クライアントがドキュメントの一貫したビューを確実に取得できるようになります。
MongoDBは、複数のドキュメントにわたるデータベーストランザクションもサポートしているため、関連する変更の一部をグループとしてロールバックまたはコミットできます。 マルチドキュメントトランザクション機能により、MongoDBは、ドキュメントモデルの柔軟性、速度、および能力を従来のデータベースのACID保証と融合させる数少ないデータベースの1つです。
アーキテクチャ/ドキュメントモデル
MongoDBのドキュメントモデルを使用すると、ユーザーはアプリケーションコード内のオブジェクトに自然にマッピングできるため、フルスタック開発者は学習と使用が容易になります。 ドキュメントは、配列やその他のより洗練された構造を簡単に格納するための階層関係を表す機能を提供します。
ネストされたサブドキュメントや配列などのフィールドにデータを格納することで、JSONドキュメントの関連情報をまとめて格納し、MongoDBクエリ言語を介してクエリにすばやくアクセスできます。
MongoDBを使用すると、バイナリJSON(BSON)と呼ばれるバイナリ表現でデータをドキュメントとして保存できます。 フィールドは、対象となるドキュメントに基づいて異なる可能性があるため、システムにドキュメントの構造を宣言する必要はありません。ドキュメントは自己記述型です。
ドキュメントに新しいフィールドを追加する必要がある場合は、コレクション内の他のドキュメントに影響を与えたり、ORMや中央システムカタログを更新したりすることなく、フィールドを生成できます。
MongoDBには、すべてのコレクションにデータガバナンス制御を適用するためのスキーマ検証のオプションも用意されています。 この柔軟性は、特に新しいアプリケーション機能が一貫して展開されているため、複数の異なるソースからの情報を照合したり、ドキュメントの変更に対応したりする場合に役立ちます。
PostgreSQLには、次の2つのプロセスで構成されるアーキテクチャのクライアントサーバーモデルが含まれています。
- クライアント側のプロセス:これらは、ユーザーがデータベースと対話するために利用するアプリケーションです。 通常、これは単純なユーザーインターフェイスを備えており、APIを介してユーザーとデータベースの間で通信するために使用されます。
- サーバー側のプロセス:これは、操作、接続、動的、および静的な資産に取り組む「Postgres」アプリケーションです。 実行中のPostgreSQLサイトは、中央の調整プロセスであるPostmasterによって処理されます。 postmasterデーモンは以下を担当します:
- リカバリの実行
- サーバーの初期化
- サーバーをシャットダウンします
- バックグラウンドプロセスの実行
- 新しいクライアントからの接続要求の管理
。
拡張性
拡張性とは、単に、新しい機能を追加できるように設計された品質のことです。
PostgreSQLは、保存された関数やプロシージャなど、いくつかの方法で拡張性をサポートしています。 PostgreSQLを広範にするのは、カタログ駆動型の操作です。
リレーショナルデータベースは、多くの場合、テーブル、データベース、列などに関する情報をシステムカタログに格納します。 これらの「データディクショナリ」は、ユーザーにはテーブルとして表示されますが、データベースシステムによって内部的に保存された情報があります。
PostgreSQLは、列とテーブルに関する情報を、存在するデータ型、関数、およびアクセス方法に関する情報とともに格納します。
さらに、PostgreSQLは動的ロードを介してユーザー作成のコードをそれ自体に組み込むこともできます。 多くの場合、ユーザーは共有ライブラリを介して実装できる特定の機能を必要とする場合があります。 ユーザーはコードファイルを指定するだけで、PostgreSQLが必要に応じてコードファイルをロードするため、新しいアプリケーションのラピッドプロトタイピングに最適です。
一方、MongoDBは最終的に拡張可能になり、ユーザーが関数を作成してフレームワーク内で使用できるようになりました。 これは、リレーショナルデータベース(PostgreSQLなど)のユーザーがSQLステートメントを拡張できるようにするユーザー定義関数(UDF)と同等です。
さらに、PostgreSQLとMongoDBはどちらも、データベース管理用のAdminerなどのいくつかの拡張機能とプラグインをサポートしています。
コラボレーションと敏捷性
MongoDBにはドキュメントモデルがあり、コラボレーションと開発をより簡単かつ迅速に実装できます。 MongoDBは、基本的にJSONまたはBSONを使用してデータをドキュメントとして保存します。
BSONには、 DateTime 、 long 、 int 、 byte arrayなど、JSONデータには存在しないいくつかのデータ型が含まれています。これらのデータ型は、ユニバーサルな「数値」型のようにすべてを処理するのではなく、データ型に応じてより具体的になるため、データをより効率的に処理できます。 JSONのようなドキュメントを効果的にアーカイブするシリアル化形式であるため、クエリの実行が高速になります。
BSONは、クエリに役立たないキーをスキップするため、データの取得が高速になります。 ユーザーは、ドキュメントの構造をさらに定義し、新しいフィールドを導入したり、データを作り直したり、適切と思われる場合はいつでもドキュメントを開発したりすることで、開発を行うことができます。
この柔軟性は、管理者にデータ定義言語ステートメントの再構築を依頼し、データベースを再作成または再ロードして最初から開始することによって発生する遅延を回避するのに役立つため、MongoDBにとって大きな利点です。
MongoDBを使用すると、開発者やチーム間のコラボレーションも簡単になります。したがって、チーム間の仲介や複雑なコミュニケーションは必要ありません。
コラボレーションに関しては、PostgreSQLにはユーザーレベルの権限、役割の継承、およびテーブルレベルの権限が含まれています。 ユーザーを管理し、ユーザーに読み取りおよび書き込み権限を付与できます。
さらに、セキュリティの追加レイヤーを付与する監査オプションを使用して、さまざまなグループまたはユーザーのデータアクセスアクティビティを確認することもできます。 ただし、PostgreSQLはデータを行と列に格納するリレーショナルデータベースであるため、MongoDBほど高速ではありません。
外部キーのサポート
MongoDBをPostgreSQLと一線を画す重要な機能は、データを保存するアプローチです。
非リレーショナルであるため、MongoDBはテーブルの代わりにコレクションを使用します。 外部キーは、別のテーブルの主キーを参照するテーブル内の属性のセットです。 外部キーは、これら2つのテーブルを相互にリンクします。
MongoDBにはテーブルがないため、MongoDBにも外部キーはありません。 したがって、外部キーの制約はありません。 ただし、MongoDBには、参照の作成を標準化するのに役立つDBRef標準があります。
一方、PostgreSQLはSQLに準拠しているため、外部キーをサポートしています。 外部キー制約を有効にすることで、PostgreSQLは外部キー列への無効なデータの挿入を停止できます。
パーティショニングとシャーディング
パーティショニングとシャーディングは、基本的に、大きなデータセットを小さなサブセットに分割することです。 シャーディングとは、データが複数のコンピューターに保存され、パーティション分割によってこのデータが単一のデータベースインスタンス内にグループ化されることを意味します。

MongoDBは、クラスター内のインスタンス間でデータを分割するため、スケーラブルです。 ドキュメントは独立したユニットであるため、ドキュメントを分割することはありません。データをローカルに保存しながら、さまざまなサーバーにドキュメントを簡単に配布できます。
MongoDB Atlasクラウドサービスを介して、データをさまざまな地域に簡単に分散できます。 また、レイテンシを確実に削減するために、特定のリージョンまたはグローバルリージョンにそれらを常に保存することを選択することもできます。
バージョン5.0以降、MongoDBには、ポリシーを設定するだけでよいため、大幅な時間の節約になる「ライブ」リシャーディング機能が含まれています。 データベースは、時が来たときにデータを自動的に再配布できます。
以前は、システムを停止せずにこれを行うことができましたが、プロセスは複雑でリスクがありました。 MongoDBにはしばらくの間グローバルなジオパーティショニングがありましたが、データはさまざまな国でさまざまな速度で増加していました。 ライブリシャーディングは、国内でローカルにとどまらなければならないデータにとって有益である可能性があります。
一方、PostgreSQLは宣言型パーティション分割をサポートしています。これは、基本的に、テーブルをパーティションに分割する方法を指定する方法です。 分割されたテーブルはパーティションテーブルと呼ばれ、仕様はパーティションメソッドで構成され、使用される列または式のリストはパーティションキーと呼ばれます。
範囲を介してパーティション化を実装できます。この場合、テーブルは、異なるパーティションに割り当てられた値の範囲間で重複することなく、キー列または列のセットによって定義された範囲でパーティション化できます。
指定されたキー値に従ってテーブルがパーティション化されるリストパーティション化を実装することもできます。
レプリケーション
レプリケーションは、複数のサーバー上に同じデータセットのコピーを作成するプロセスです。 これにより、データベース管理者は、高いデータ冗長性と高いデータ可用性を提供できます。
MongoDBの場合、これは「レプリカセット」を使用することで実現されます。これは、サーバー間でデータを複製し続ける3つ以上のサーバーで構成される同期クラスターです。 これにより、メンテナンスのためにスケジュールされた中断やシステム障害が発生した場合に発生する可能性のあるダウンタイムに対する冗長性と保護が提供され、データベースのフォールトトレランスが向上します。
レプリカセットは、地域の停止時に役立つため、さまざまなデータセンターに実装することもできます。 これはMongoDBAtlasによって実行できます。これにより、これらのクラスターの構築と構成がより簡単かつ迅速になります。
PostgreSQLはプライマリ-セカンダリレプリケーションを提供します。 ログ先行書き込みにより、レプリカノードで行われた変更を共有できるため、非同期レプリケーションが可能になります。 他の種類のレプリケーションには、論理レプリケーション、ストリーミングレプリケーション、および物理レプリケーションが含まれます。
インデックス
インデックスは、特定の行またはデータをより高速に取得できるようにするオブジェクトまたは構造です。
PostgreSQLは、あらゆるクエリワークロードに効率的に一致するさまざまな一意のインデックスタイプを提供します。 そのインデックス作成手法には、Bツリー、複数列、および式が含まれます。 さらに、GiST、KNN Gist、SP-Gist、GIN、BRIN、カバーインデックス、ブルームフィルターなどの部分的および高度なインデックス作成手法もPostgreSQLに実装できます。
一方、MongoDBを使用すると、配列やサブドキュメントにどれほど深くネストされていても、インデックス作成によってすばやくアクセスできる任意の構造にデータを格納できます。
言語と構文
MongoDBとPostgreSQLはどちらも、さまざまな言語をサポートしています。
MongoDBは、Python、R、Java、Scala、C、C ++、C#、Node.jsなどの最高のデータベース言語のドライバーサポートを提供します。 これらのMongoDBライブラリとドライバーは、MongoDBのすべての機能をサポートし、すべてのアプリケーションで高いパフォーマンスとスケーラビリティを提供します。
PostgreSQLは、PL / pgSQL、PL / Python、PL / Perl、PL / Tclなどの基本ディストリビューションと、PL / Java、PL / PHP、PL /などのコアPostgreSQLディストリビューションの外部で開発および保守されている他の言語を使用して、いくつかの手続き型言語をサポートします。 Ruby。
正規化
正規化は、データの冗長性を減らし、データ変更の異常を最小限に抑え、データの整合性を向上させるためにリレーショナルデータベースを構築するプロセスです。
MongoDBは、正規化されたデータモデルと非正規化されたデータモデル(埋め込みモデルとも呼ばれます)の両方を処理できます。
組み込みモデルを使用すると、アプリケーションは関連する情報を同じデータベースレコードに格納できます。これにより、読み取り操作のパフォーマンスが向上し、単一のデータベース操作で関連データを取得できるようになります。
さらに、アプリケーションが一般的な操作を完了するために発行するクエリを減らしながら、単一のアトミック書き込み操作で関連データを更新することもできます。 埋め込みデータモデルのMongoDB内のドキュメントは、最大BSONドキュメントサイズ(16 MB)よりも小さくする必要があります。
正規化されたデータモデルは、ドキュメント間の参照を使用して関係を記述します。 これは、埋め込みによってデータの重複が発生する可能性がある場合に使用すると便利ですが、読み取りパフォーマンスの利点が不十分な場合、重複の影響を上回ります。
ただし、パフォーマンスを向上させるためにデータベース内の以前に正規化されたデータがグループ化されている場合、非正規化プロセスは通常、高いメモリ消費を引き起こします。
PostgreSQLスキーマには識別された関係があります。 構造は、1:1、1:多、または多:1の関係で識別できます。 データの正規化は、データの冗長なコピーを削除し、整合性を確保するため、非常に有益です。
パフォーマンス
MongoDBとPostgreSQLはどちらもデータの保存と取得の方法が異なるため、2つの異なるデータベースシステムのパフォーマンスを評価することは困難です。
MongoDBは、その能力を追加のマシンと組み合わせることが多く、処理能力に依存しないため、水平方向にスケールアウトするように構築されています。 データサイズやユーザーによる測定に関係なく、大規模なアプリケーションに電力を供給することができます。
MongoDBは、クエリの高速実行を必要とし、大量のデータを処理できるユースケースにも対応できます。 全体で数百台のマシンを組み込むことができます。
MongoDB 4.4以降、レプリカセットに対して実装されたクエリは、「ヘッジされた」読み取りを通じて改善された予測可能なパフォーマンスを生成します。 これらの読み取りは、最速のノードが応答するまで、レプリカセット内の複数のノードに送信されます。
PostgreSQLは、生の挿入速度の点ではMongoDBほど高速ではありませんが、ACID準拠の点では優れています。 トランザクションは安全かつ確実に処理されるため、部分的に成功した書き込みを実行する代わりに、トランザクション全体を失敗させることができます。
MongoDBは、SQLデータベースと同様のACIDトランザクションのサポートを最近(バージョン4で)開始しました。
MongoDBとは異なり、PostgreSQLはデータボリュームとスケーリング書き込みのスケールアップ戦略(垂直スケーリング)に依存しています。 これは、ディスク、CPU、メモリなどのハードウェアリソースを既存のデータベースノードに追加することによって実行されます。
ただし、PostgreSQLは、成熟したクエリプランナー、式のジャストインタイム(JIT)コンパイル、テーブルのパーティション分割、読み取りクエリの並列化など、パフォーマンスの最適化に向けていくつかの努力を払ってきました。
価格
PostgreSQLは完全に無料でオープンソースです。 したがって、誰でもその機能を使用して、必要に応じてコードを簡単に変更できます。
MongoDBはオープンソースツールでもあります。 ただし、MongoDBには、エンタープライズやAtlas(クラウド用)など、価格が異なる他のオプションがあります。 MongoDB Enterprise Editionには、オンプレミスの価格設定モデルが用意されています。
Mongo RealmDBは、すべてのAtlasユーザーが評価と軽い使用のために無料で利用できるため、開発者はモバイルアプリケーションを構築およびリリースできます。
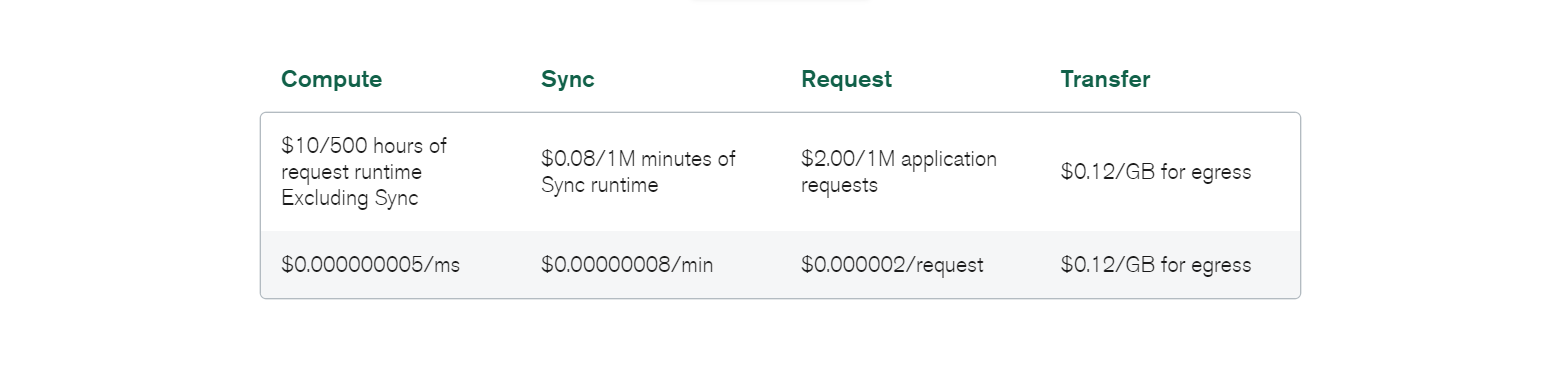
データ移行によってもオーバーヘッドが発生する可能性があります。 ただし、これは、システムに実装したデータベースに関係なく標準です。
クエリ処理
PostgreSQLは、テーブル内にデータを格納し、データベースアクセスに構造化クエリ言語(SQL)を利用することに依存するリレーショナルデータベースモデルを使用します。 SQLコマンドは、PostgreSQLターミナルpsqlを使用して入力できます。 ラージオブジェクト機能があり、特別なラージオブジェクト構造に格納されているユーザーデータへのストリームスタイルのアクセスを提供します。
データを追加する前に、データベーススキーマを構築して、クエリを処理するためのデータの関係を明確に理解する必要があります。 関連情報は、データベース内の個別のテーブルに保存できます。 これには、外部キーと結合を介してアクセスできます。
データベースがロードされると、データベースの構造を調整するのが難しい場合があります。 構造に加えられた変更を注意深く調整するには、開発、運用、およびデータベース管理者の複数のチームが必要です。
一方、MongoDBのデータ構造は、基本的に非構造化データを処理するため、事前に計画する必要はありません。 データ構造もはるかに簡単に調整できます。
開発者は、アプリケーションに不可欠なものを選択し、必要な変更を加えることができます。 MongoDBはMQLを使用します。これは、MongoDB内のドキュメントを操作し、SQLのような柔軟性とパワーを提供しながらデータを取り出すために使用できます。
MongoDBは、データをJSONドキュメントとして処理します。 JSONドキュメント内のフィールドをクエリすることもできます。 したがって、MongoDBは、柔軟なデータフィールド内にドキュメントを保存する場合に非常に役立ちます。
PostgreSQLはGROUP_BY関数を使用して集計クエリを処理および実行しますが、MongoDBは通常、集計パイプラインを使用してクエリを処理します。
ただし、MongoDBの主な欠点の1つは、テーブルを簡単に結合できないことです。 PostgreSQLでは、JOINステートメントを使用して簡単に作成できます。
MongoDBは、あるドキュメントストアを別のドキュメントストアに埋め込むことができる多次元データ型を導入することで、これを解決しようとしました。 ただし、これはまとまりがなく、PostgreSQLに組み込まれている単純なjoin関数ほど洗練されていません。
安全
セキュリティに関しては、PostgreSQLがMongoDBよりも優れています。 データベースの構造を管理する厳格なルールにより、PostgreSQLは非常に安全なデータベースになるため、銀行システムでの使用が信頼できます。
PostgreSQLは、プラガブル認証モジュール(PAM)やライトウェイトディレクトリアクセスプロトコル(LDAP)など、サーバーの攻撃対象領域を減らすための多数の認証方法を提供します。 また、ホストベースの認証と証明書認証を通じてサーバーレベルの保護を保証します。
さらに、PostgreSQLはデータ暗号化を提供し、データがWebまたはパブリックネットワークの高速道路を通過するときにSSL証明書を使用できるようにします。 PostgreSQLでは、オプションとしてクライアント証明書認証(CCA)ツールを実装し、暗号化されたデータをPostgreSQLに保存するために暗号化機能を使用することもできます。
ただし、PostgreSQLのセキュリティレベルは、同じデータベースであっても、クラウドシステムごとに異なる場合があります。
MongoDB Atlasは、3つの最大のクラウドプロバイダー間で同じように機能し、複数のクラウド間の移行を容易にします。
さらに、MongoDBにはクライアント側およびフィールドレベルの暗号化機能があり、ユーザーはデータをネットワーク経由でデータベースに送信する前に暗号化できます。 ただし、データは1つのレコードにキーと値のペアで格納されるため、PostgreSQLが誇るセキュリティが不足しています。 MongoDBの主な焦点は、引き続き速度です。
サポートとコミュニティ
PostgreSQLは完全にオープンソースであり、コミュニティによってサポートされているため、完全なエコシステムとして強化されています。 PostgreSQLは頻繁に更新バージョンを定期的にリリースしており、開発者、愛好家、またはサードパーティ企業がサポートを提供し、バグを修正したり、データベースシステムにわずかな変更を加えたりしてシステムの開発を試みています。
PostgreSQLと同様に、MongoDBにもコミュニティフォーラムがあり、ユーザーは他の複数のユーザーとつながり、一般的な質問に答えることができます。 MongoDBエンタープライズサポートには、ユースケース、詳細なチュートリアル、最適化に関するテクニカルノート、およびベストプラクティスを含む広範なナレッジベースをさらに含めることができます。
さらに、MongoDBが無料で提供するトレーニングと認定を含むオンラインコースがあります。
課題
MongoDBとPostgreSQLの両方の機能について説明しましたが、それらは開発者に人気がありますが、弱点もかなりあります。
MongoDBは高速データ操作に重点を置く傾向がありますが、PostgreSQLが備えていると思われるデータセキュリティが不足しています。 非正規化プロセスは通常、高いメモリ消費をもたらすため、これはメモリにかなりの負担をかけます。
さらに、結合がサポートされていないため、MongoDBデータベースにはデータが過剰に供給されており(重複している場合もあります)、メモリに大きな負担がかかります。 MongoDBは、拡張性の一部として他のクエリ言語への解釈を含めることも試みました。 ただし、データベースは当初、リレーショナルデータモデルを処理するように構築されていなかったため、パフォーマンスが低下する可能性があります。
SQLからMongoDBクエリへの変換には、エンジンの使用に追加の時間がかかる場合があり、デプロイメントと開発が遅れる可能性があります。
一方、PostgreSQLはインストールが簡単で、ほとんどすべてのプラットフォームに適応できますが、その効率はプラットフォームごとに異なる場合があります。 さらに、データベースの現在の状態を示すことができる修正ツールやレポート手段がありません。 手遅れになったときに障害に気付かないようにするために、何かが計画どおりに進まない場合は、データベースを継続的にチェックする必要がある場合があります。
PostgreSQLは互換性に重点を置いているため、少し遅くなります。 PostgreSQLの速度を向上させるための努力がなされてきましたが、変更にはまだもう少し作業が必要です。
MongoDBとPostgreSQL:どちらを選択する必要がありますか?
MongoDBは非リレーショナルデータベースですが、PostgreSQLはリレーショナルデータベースです。 NoSQLデータベースはデータをキーと値のペアで1つのレコードとして格納するように機能しますが、リレーショナルデータベースはデータを異なるテーブルに格納します。
複数のサーバー間でより高速なデータ統合とスケーラビリティを優先する場合は、MongoDBがビジネスに適した選択肢となる可能性があります。
MongoDBの速度は、ユーザーの行動をリアルタイムで追跡するのに役立つ動的なパフォーマンスを提供するため、MongoDBは分析プラットフォームに統合されたときに最適に機能します。 New York Times(実際にはMongoDBを使用)のような構造化スキーマに依存しない忙しいWebアプリケーションを所有している場合や、必要な製品カタログを所有している場合にも、ビジネスに非常に役立ちます。さまざまな属性コレクションを持つ複数のオブジェクトを格納します。
一方、PostgreSQLはデータ分析とウェアハウジングに最適です。 データセキュリティとトランザクション保証を適用したいデータベース自動化ツールまたは銀行アプリケーションを構築している場合は、PostgreSQLが最適です。
概要
要約すると、これまで、PostgreSQLとMongoDBの基本的な詳細についても説明してきました。 それらの歴史、主な機能、およびそれらの違いについて説明しました。
PostgreSQLとMongoDBはどちらもすばらしいデータベースを作成しますが、最終的にはビジネスに最適なものを選択することになります。
PostgreSQLとMongoDBの間で、どちらのデータベースが好きですか? コメントで教えてください!