
Como criar um banco de dados MongoDB: 6 aspectos críticos a serem conhecidos
Publicados: 2022-11-07Com base em seus requisitos para seu software, você pode priorizar flexibilidade, escalabilidade, desempenho ou velocidade. Portanto, desenvolvedores e empresas geralmente ficam confusos ao escolher um banco de dados para suas necessidades. Se você precisa de um banco de dados que forneça alta flexibilidade e escalabilidade e agregação de dados para análise de clientes, o MongoDB pode ser a opção certa para você!
Neste artigo, discutiremos a estrutura do banco de dados MongoDB e como criar, monitorar e gerenciar seu banco de dados! Vamos começar.
Como um banco de dados MongoDB é estruturado?
MongoDB é um banco de dados NoSQL sem esquema. Isso significa que você não especifica uma estrutura para as tabelas/bancos de dados como faz para bancos de dados SQL.
Você sabia que os bancos de dados NoSQL são realmente mais rápidos que os bancos de dados relacionais? Isso se deve a características como indexação, fragmentação e pipelines de agregação. O MongoDB também é conhecido por sua rápida execução de consultas. É por isso que é preferido por empresas como Google, Toyota e Forbes.
Abaixo, exploraremos algumas das principais características do MongoDB.
Documentos
O MongoDB possui um modelo de dados de documento que armazena dados como documentos JSON. Os documentos são mapeados naturalmente para os objetos no código do aplicativo, tornando o uso mais simples para os desenvolvedores.
Em uma tabela de banco de dados relacional, você deve adicionar uma coluna para adicionar um novo campo. Esse não é o caso dos campos em um documento JSON. Os campos em um documento JSON podem diferir de documento para documento, portanto, não serão adicionados a todos os registros do banco de dados.
Os documentos podem armazenar estruturas como matrizes que podem ser aninhadas para expressar relacionamentos hierárquicos. Além disso, o MongoDB converte documentos em um tipo binário JSON (BSON). Isso garante acesso mais rápido e maior suporte para vários tipos de dados, como string, inteiro, número booleano e muito mais!
Conjuntos de réplicas
Quando você cria um novo banco de dados no MongoDB, o sistema cria automaticamente pelo menos mais 2 cópias de seus dados. Essas cópias são conhecidas como “conjuntos de réplicas” e replicam dados continuamente entre elas, garantindo maior disponibilidade de seus dados. Eles também oferecem proteção contra tempo de inatividade durante uma falha do sistema ou manutenção planejada.
Coleções
Uma coleção é um grupo de documentos associados a um banco de dados. Eles são semelhantes às tabelas em bancos de dados relacionais.
As coleções, no entanto, são muito mais flexíveis. Por um lado, eles não dependem de um esquema. Em segundo lugar, os documentos não precisam ser do mesmo tipo de dados!
Para visualizar uma lista das coleções que pertencem a um banco de dados, use o comando listCollections .
Pipelines de agregação
Você pode usar essa estrutura para agrupar vários operadores e expressões. É flexível porque permite processar, transformar e analisar dados de qualquer estrutura.
Por isso, o MongoDB permite fluxos de dados rápidos e recursos em 150 operadores e expressões. Também possui vários estágios, como o estágio Union, que reúne de forma flexível os resultados de várias coletas.
Índices
Você pode indexar qualquer campo em um documento do MongoDB para aumentar sua eficiência e melhorar a velocidade de consulta. A indexação economiza tempo digitalizando o índice para limitar os documentos inspecionados. Isso não é muito melhor do que ler todos os documentos da coleção?
Você pode usar várias estratégias de indexação, incluindo índices compostos em vários campos. Por exemplo, digamos que você tenha vários documentos contendo o nome e sobrenome do funcionário em campos separados. Se desejar que o nome e o sobrenome sejam retornados, você pode criar um índice que inclua “Sobrenome” e “Nome”. Isso seria muito melhor do que ter um índice em “Sobrenome” e outro em “Nome”.
Você pode aproveitar ferramentas como o Performance Advisor para entender melhor qual consulta pode se beneficiar dos índices.
Fragmentação
A fragmentação distribui um único conjunto de dados em vários bancos de dados. Esse conjunto de dados pode ser armazenado em várias máquinas para aumentar a capacidade total de armazenamento de um sistema. Isso ocorre porque ele divide conjuntos de dados maiores em partes menores e os armazena em vários nós de dados.
O MongoDB fragmenta dados no nível da coleção, distribuindo documentos em uma coleção entre os fragmentos em um cluster. Isso garante escalabilidade, permitindo que a arquitetura lide com os maiores aplicativos.
Como criar um banco de dados MongoDB
Você precisará instalar primeiro o pacote MongoDB adequado para o seu sistema operacional. Vá para a página 'Baixar o MongoDB Community Server'. Entre as opções disponíveis, selecione a “versão” mais recente, o formato “pacote” como arquivo zip e “plataforma” como seu sistema operacional e clique em “Download” conforme ilustrado abaixo:
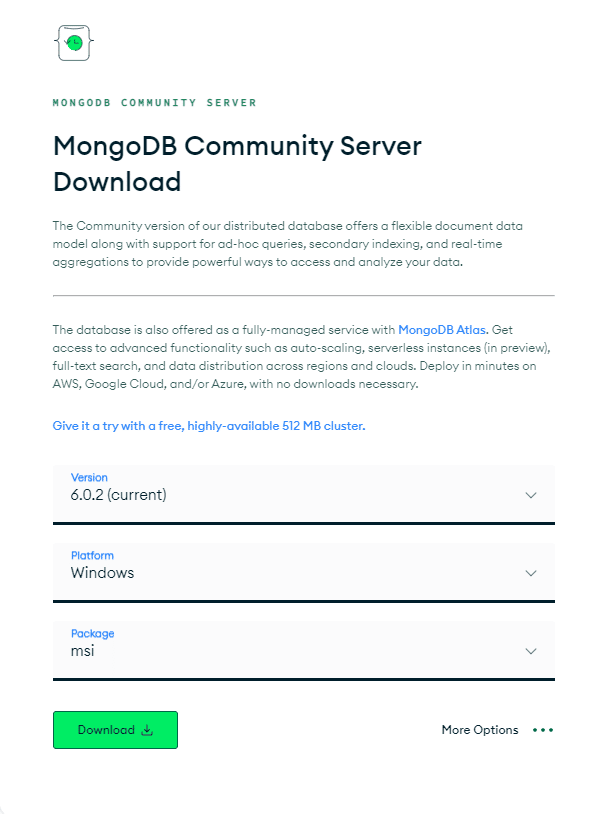
O processo é bastante simples, então você terá o MongoDB instalado em seu sistema rapidamente!
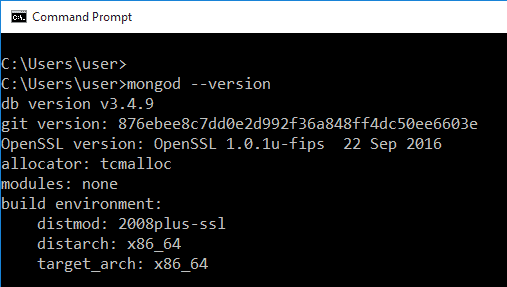
Depois de fazer a instalação, abra o prompt de comando e digite mongod -version para verificá-lo. Se você não obtiver a seguinte saída e, em vez disso, vir uma sequência de erros, talvez seja necessário reinstalá-la:
Usando o MongoDB Shell
Antes de começarmos, certifique-se de que:
- Seu cliente tem Transport Layer Security e está na sua lista de permissões de IP.
- Você tem uma conta de usuário e senha no cluster MongoDB desejado.
- Você instalou o MongoDB no seu dispositivo.
Etapa 1: acessar o Shell do MongoDB
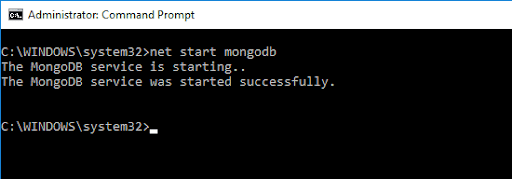
Para obter acesso ao shell do MongoDB, digite o seguinte comando:
net start MongoDBIsso deve dar a seguinte saída:
O comando anterior inicializou o servidor MongoDB. Para executá-lo, teríamos que digitar mongo no prompt de comando.
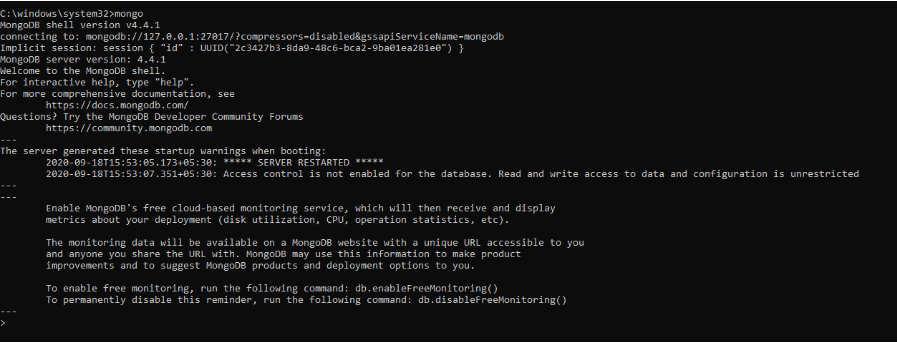
Aqui no shell do MongoDB, podemos executar comandos para criar bancos de dados, inserir dados, editar dados, emitir comandos administrativos e excluir dados.
Etapa 2: crie seu banco de dados
Ao contrário do SQL, o MongoDB não possui um comando de criação de banco de dados. Em vez disso, há uma palavra-chave chamada use que alterna para um banco de dados especificado. Se o banco de dados não existir, ele criará um novo banco de dados, caso contrário, será vinculado ao banco de dados existente.
Por exemplo, para iniciar um banco de dados chamado “empresa”, digite:
use Company 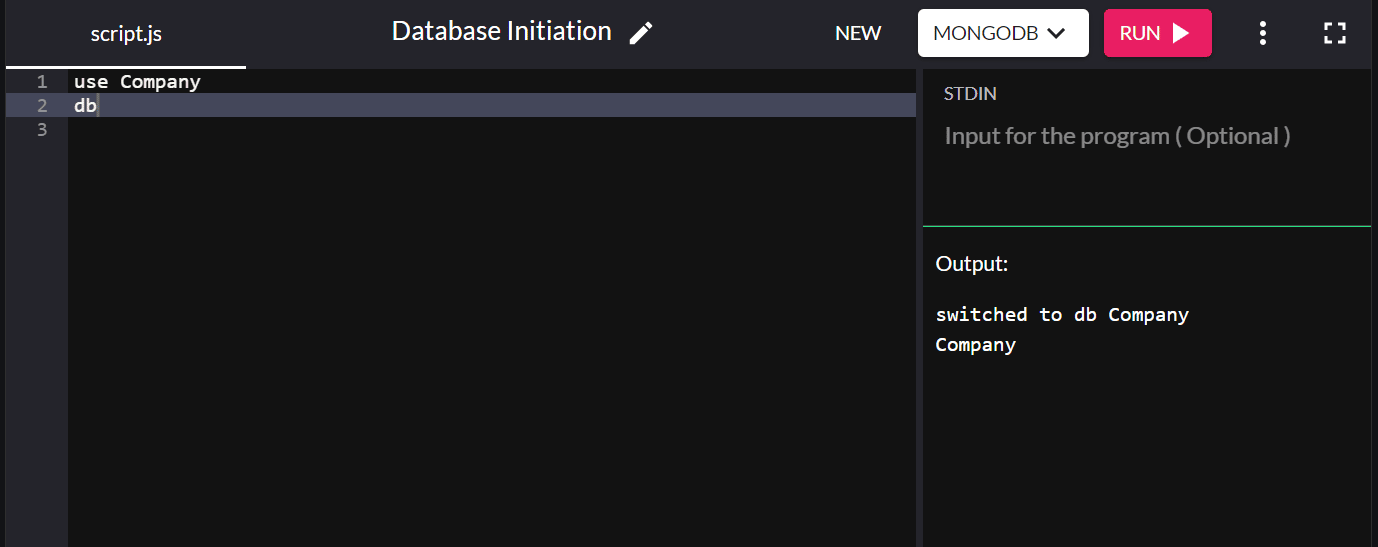
Você pode digitar db para confirmar o banco de dados que acabou de criar em seu sistema. Se o novo banco de dados que você criou aparecer, você se conectou a ele com sucesso.
Se você quiser verificar os bancos de dados existentes, digite show dbs e ele retornará todos os bancos de dados do seu sistema:

Por padrão, a instalação do MongoDB cria os bancos de dados admin, config e local.
Você notou que o banco de dados que criamos não é exibido? Isso ocorre porque ainda não salvamos valores no banco de dados! Discutiremos a inserção na seção de gerenciamento de banco de dados.
Como usar a interface do usuário do Atlas
Você também pode começar com o serviço de banco de dados do MongoDB, Atlas. Embora você precise pagar para acessar alguns recursos do Atlas, a maioria das funcionalidades do banco de dados está disponível com o nível gratuito. Os recursos do nível gratuito são mais do que suficientes para criar um banco de dados MongoDB.
Antes de começarmos, certifique-se de que:
- Seu IP está na lista de permissões.
- Você tem uma conta de usuário e senha no cluster MongoDB que deseja usar.
Para criar um banco de dados MongoDB com AtlasUI, abra uma janela do navegador e faça login em https://cloud.mongodb.com. Na página do cluster, clique em Procurar coleções . Se não houver bancos de dados no cluster, você poderá criar seu banco de dados clicando no botão Adicionar meus próprios dados .
O prompt solicitará que você forneça um banco de dados e um nome de coleção. Depois de nomeá-los, clique em Criar e pronto! Agora você pode inserir novos documentos ou conectar-se ao banco de dados usando drivers.
Gerenciando seu banco de dados MongoDB
Nesta seção, veremos algumas maneiras interessantes de gerenciar seu banco de dados MongoDB com eficiência. Você pode fazer isso usando o MongoDB Compass ou por meio de coleções.
Usando coleções
Enquanto os bancos de dados relacionais possuem tabelas bem definidas com tipos de dados e colunas especificados, o NoSQL possui coleções em vez de tabelas. Essas coleções não têm nenhuma estrutura e os documentos podem variar — você pode ter diferentes tipos de dados e campos sem precisar corresponder ao formato de outro documento na mesma coleção.
Para demonstrar, vamos criar uma coleção chamada “Employee” e adicionar um documento a ela:
db.Employee.insert( { "Employeename" : "Chris", "EmployeeDepartment" : "Sales" } ) Se a inserção for bem-sucedida, retornará WriteResult({ "nInserted" : 1 }) :
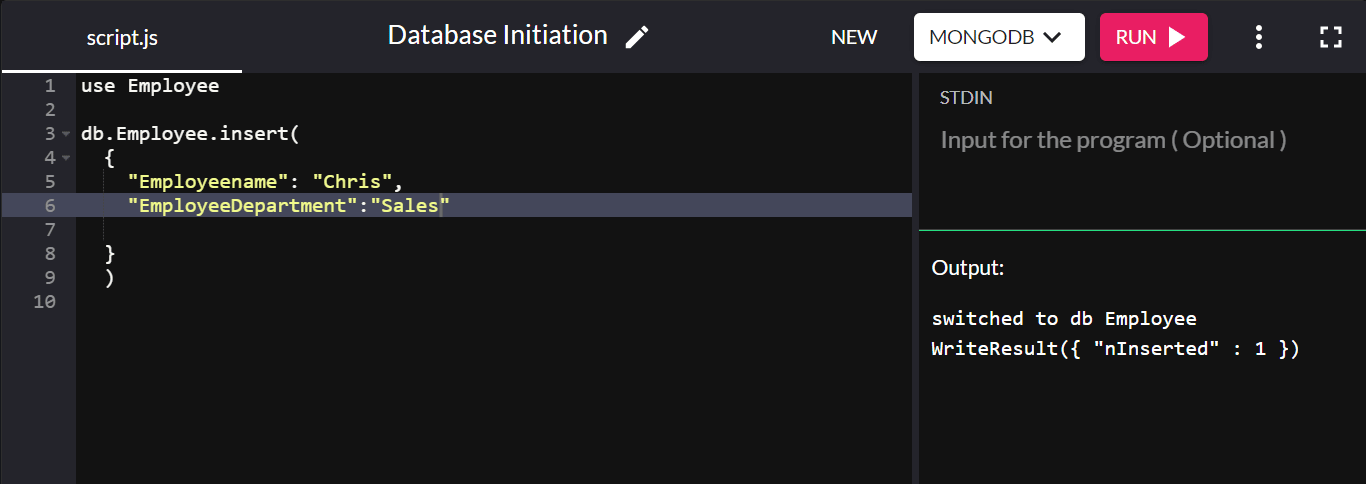
Aqui, “db” refere-se ao banco de dados conectado no momento. “Employee” é a coleção recém-criada no banco de dados da empresa.
Não definimos uma chave primária aqui porque o MongoDB cria automaticamente um campo de chave primária chamado “_id” e define um valor padrão para ele.
Execute o comando abaixo para verificar a coleção no formato JSON:
db.Employee.find().forEach(printjson)Resultado:
{ "_id" : ObjectId("63151427a4dd187757d135b8"), "Employeename" : "Chris", "EmployeeDepartment" : "Sales" }Embora o valor “_id” seja atribuído automaticamente, você pode alterar o valor da chave primária padrão. Desta vez, vamos inserir outro documento no banco de dados “Employee”, com o valor “_id” como “1”:
db.Employee.insert( { "_id" : 1, "EmployeeName" : "Ava", "EmployeeDepartment" : "Public Relations" } ) Ao executar o comando db.Employee.find().forEach(printjson) obtemos a seguinte saída:
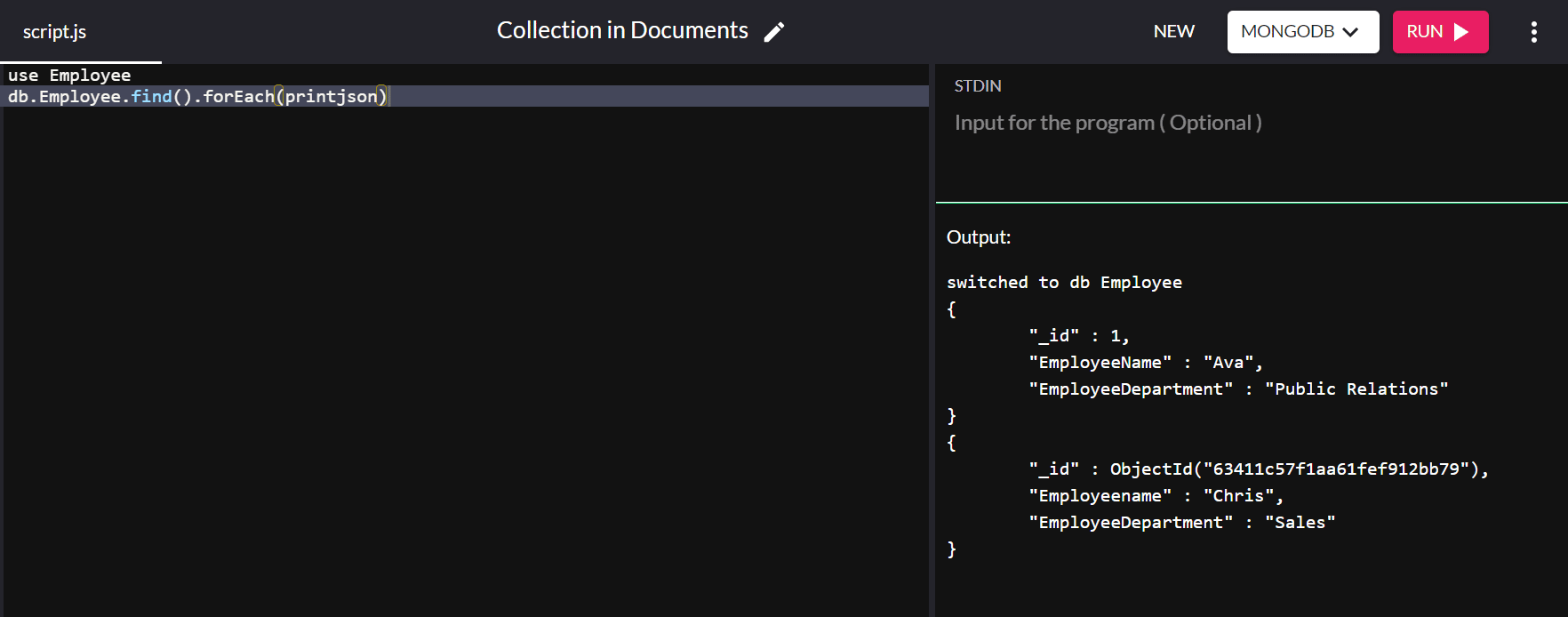
Na saída acima, o valor “_id” para “Ava” é definido como “1” em vez de receber um valor automaticamente.
Agora que adicionamos valores ao banco de dados com sucesso, podemos verificar se ele aparece nos bancos de dados existentes em nosso sistema usando o seguinte comando:
show dbs 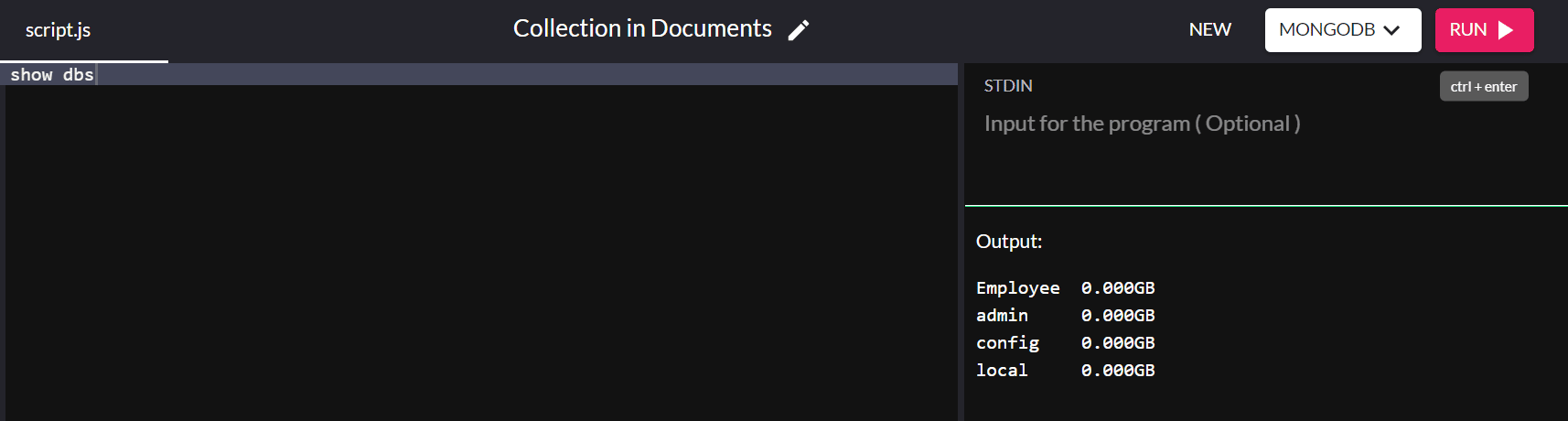
E voilá! Você criou com sucesso um banco de dados em seu sistema!
Usando a bússola do MongoDB
Embora possamos trabalhar com servidores MongoDB a partir do shell do Mongo, às vezes pode ser tedioso. Você pode experimentar isso em um ambiente de produção.
No entanto, existe uma ferramenta de bússola (apropriadamente chamada Compass) criada pelo MongoDB que pode facilitar. Ele tem uma GUI melhor e funcionalidades adicionadas, como visualização de dados, perfil de desempenho e acesso CRUD (criar, ler, atualizar, excluir) a dados, bancos de dados e coleções.
Você pode baixar o Compass IDE para o seu sistema operacional e instalá-lo com seu processo simples.
Em seguida, abra o aplicativo e crie uma conexão com o servidor colando a string de conexão. Se não conseguir encontrá-lo, clique em Preencher os campos de conexão individualmente . Se você não alterou o número da porta durante a instalação do MongoDB, basta clicar no botão conectar e pronto! Caso contrário, basta inserir os valores definidos e clicar em Conectar .
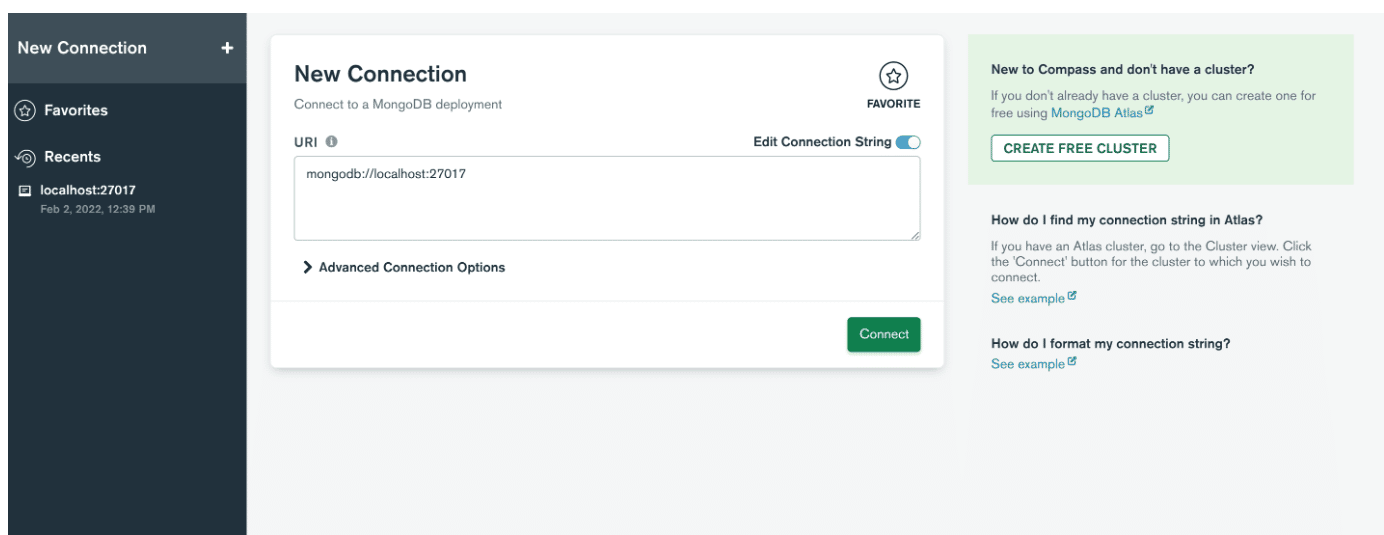
Em seguida, forneça o Hostname, Port e Authentication na janela New Connection.
No MongoDB Compass, você pode criar um banco de dados e adicionar sua primeira coleção simultaneamente. Aqui está como você faz isso:
- Clique em Criar banco de dados para abrir o prompt.
- Insira o nome do banco de dados e sua primeira coleção.
- Clique em Criar banco de dados.
Você pode inserir mais documentos em seu banco de dados clicando no nome do banco de dados e, em seguida, clicando no nome da coleção para ver a guia Documentos . Você pode clicar no botão Adicionar dados para inserir um ou mais documentos em sua coleção.
Ao adicionar seus documentos, você pode inseri-los um de cada vez ou como vários documentos em uma matriz. Se você estiver adicionando vários documentos, certifique-se de que esses documentos separados por vírgulas estejam entre colchetes. Por exemplo:
{ _id: 1, item: { name: "apple", code: "123" }, qty: 15, tags: [ "A", "B", "C" ] }, { _id: 2, item: { name: "banana", code: "123" }, qty: 20, tags: [ "B" ] }, { _id: 3, item: { name: "spinach", code: "456" }, qty: 25, tags: [ "A", "B" ] }, { _id: 4, item: { name: "lentils", code: "456" }, qty: 30, tags: [ "B", "A" ] }, { _id: 5, item: { name: "pears", code: "000" }, qty: 20, tags: [ [ "A", "B" ], "C" ] }, { _id: 6, item: { name: "strawberry", code: "123" }, tags: [ "B" ] }Por fim, clique em Inserir para adicionar os documentos à sua coleção. Esta é a aparência do corpo de um documento:
{ "StudentID" : 1 "StudentName" : "JohnDoe" }Aqui, os nomes dos campos são “StudentID” e “StudentName”. Os valores do campo são “1” e “JohnDoe”, respectivamente.
Comandos úteis
Você pode gerenciar essas coleções por meio de comandos de gerenciamento de funções e gerenciamento de usuários.
Comandos de gerenciamento de usuários
Os comandos de gerenciamento de usuários do MongoDB contêm comandos que pertencem ao usuário. Podemos criar, atualizar e excluir os usuários usando esses comandos.
dropUser
Este comando remove um único usuário do banco de dados especificado. Segue abaixo a sintaxe:
db.dropUser(username, writeConcern) Aqui, nome de username é um campo obrigatório que contém o documento com informações de autenticação e acesso sobre o usuário. O campo opcional writeConcern contém o nível de preocupação de gravação para a operação de criação. O nível de preocupação de gravação pode ser determinado pelo campo opcional writeConcern .
Antes de descartar um usuário que tenha a função userAdminAnyDatabase , certifique-se de que haja pelo menos um outro usuário com privilégios de administração de usuário.
Neste exemplo, descartaremos o usuário “user26” no banco de dados de teste:
use test db.dropUser("user26", {w: "majority", wtimeout: 4000})Resultado:
> db.dropUser("user26", {w: "majority", wtimeout: 4000}); truecriarUsuário
Este comando cria um novo usuário para o banco de dados especificado da seguinte forma:
db.createUser(user, writeConcern) Aqui, user é um campo obrigatório que contém o documento com autenticação e informações de acesso sobre o usuário a ser criado. O campo opcional writeConcern contém o nível de preocupação de gravação para a operação de criação. O nível de preocupação de gravação pode ser determinado pelo campo opcional, writeConcern .
createUser retornará um erro de usuário duplicado se o usuário já existir no banco de dados.
Você pode criar um novo usuário no banco de dados de teste da seguinte maneira:
use test db.createUser( { user: "user26", pwd: "myuser123", roles: [ "readWrite" ] } );A saída é a seguinte:
Successfully added user: { "user" : "user26", "roles" : [ "readWrite", "dbAdmin" ] }grantRolesToUser
Você pode aproveitar esse comando para conceder funções adicionais a um usuário. Para usá-lo, você precisa manter a seguinte sintaxe em mente:
db.runCommand( { grantRolesToUser: "<user>", roles: [ <roles> ], writeConcern: { <write concern> }, comment: <any> } ) Você pode especificar funções definidas pelo usuário e internas nas funções mencionadas acima. Se você deseja especificar uma função que existe no mesmo banco de dados em que grantRolesToUser é executado, você pode especificar a função com um documento, conforme mencionado abaixo:
{ role: "<role>", db: "<database>" }Ou você pode simplesmente especificar a função com o nome da função. Por exemplo:
"readWrite"Se você quiser especificar a função que está presente em um banco de dados diferente, precisará especificar a função com um documento diferente.
Para conceder uma função em um banco de dados, você precisa da ação grantRole no banco de dados especificado.
Aqui está um exemplo para lhe dar uma imagem clara. Tomemos, por exemplo, um usuário productUser00 no banco de dados de produtos com as seguintes funções:
"roles" : [ { "role" : "assetsWriter", "db" : "assets" } ] A operação grantRolesToUser fornece a “productUser00” a função readWrite no banco de dados de estoque e a função read no banco de dados de produtos:
use products db.runCommand({ grantRolesToUser: "productUser00", roles: [ { role: "readWrite", db: "stock"}, "read" ], writeConcern: { w: "majority" , wtimeout: 2000 } })O usuário productUser00 no banco de dados de produtos agora possui as seguintes funções:
"roles" : [ { "role" : "assetsWriter", "db" : "assets" }, { "role" : "readWrite", "db" : "stock" }, { "role" : "read", "db" : "products" } ]informações de usuários
Você pode usar o comando usersInfo para retornar informações sobre um ou mais usuários. Aqui está a sintaxe:
db.runCommand( { usersInfo: <various>, showCredentials: <Boolean>, showCustomData: <Boolean>, showPrivileges: <Boolean>, showAuthenticationRestrictions: <Boolean>, filter: <document>, comment: <any> } ) { usersInfo: <various> } Em termos de acesso, os utilizadores podem sempre consultar a sua própria informação. Para consultar as informações de outro usuário, o usuário que executa o comando deve ter privilégios que incluam a ação viewUser no banco de dados do outro usuário.
Ao executar o comando userInfo , você pode obter as seguintes informações dependendo das opções especificadas:
{ "users" : [ { "_id" : "<db>.<username>", "userId" : <UUID>, // Starting in MongoDB 4.0.9 "user" : "<username>", "db" : "<db>", "mechanisms" : [ ... ], // Starting in MongoDB 4.0 "customData" : <document>, "roles" : [ ... ], "credentials": { ... }, // only if showCredentials: true "inheritedRoles" : [ ... ], // only if showPrivileges: true or showAuthenticationRestrictions: true "inheritedPrivileges" : [ ... ], // only if showPrivileges: true or showAuthenticationRestrictions: true "inheritedAuthenticationRestrictions" : [ ] // only if showPrivileges: true or showAuthenticationRestrictions: true "authenticationRestrictions" : [ ... ] // only if showAuthenticationRestrictions: true }, ], "ok" : 1 } Agora que você tem uma ideia geral do que pode realizar com o comando usersInfo , a próxima pergunta óbvia que pode surgir é: quais comandos seriam úteis para examinar usuários específicos e vários usuários?
Aqui estão dois exemplos úteis para ilustrar o mesmo:
Para ver os privilégios e informações específicos de usuários específicos, mas não as credenciais, para um usuário “Anthony” definido no banco de dados “office”, execute o seguinte comando:
db.runCommand( { usersInfo: { user: "Anthony", db: "office" }, showPrivileges: true } )Se você quiser ver um usuário no banco de dados atual, só poderá mencioná-lo pelo nome. Por exemplo, se você estiver no banco de dados inicial e um usuário chamado “Timothy” existir no banco de dados inicial, você poderá executar o seguinte comando:
db.getSiblingDB("home").runCommand( { usersInfo: "Timothy", showPrivileges: true } ) Em seguida, você pode usar uma matriz se desejar ver as informações de vários usuários. Você pode incluir os campos opcionais showCredentials e showPrivileges ou pode optar por deixá-los de fora. Esta é a aparência do comando:
db.runCommand({ usersInfo: [ { user: "Anthony", db: "office" }, { user: "Timothy", db: "home" } ], showPrivileges: true })revogarRolesFromUser
Você pode aproveitar o comando revokeRolesFromUser para remover uma ou mais funções de um usuário no banco de dados em que as funções estão presentes. O comando revokeRolesFromUser tem a seguinte sintaxe:
db.runCommand( { revokeRolesFromUser: "<user>", roles: [ { role: "<role>", db: "<database>" } | "<role>", ], writeConcern: { <write concern> }, comment: <any> } ) Na sintaxe mencionada acima, você pode especificar funções definidas pelo usuário e incorporadas no campo de roles . Semelhante ao comando grantRolesToUser , você pode especificar a função que deseja revogar em um documento ou usar seu nome.
Para executar com sucesso o comando revokeRolesFromUser , você precisa ter a ação revokeRole no banco de dados especificado.
Aqui está um exemplo para levar o ponto para casa. A entidade productUser00 no banco de dados de produtos tinha as seguintes funções:
"roles" : [ { "role" : "assetsWriter", "db" : "assets" }, { "role" : "readWrite", "db" : "stock" }, { "role" : "read", "db" : "products" } ] O seguinte comando revokeRolesFromUser removerá duas das funções do usuário: a função “read” dos products e a função assetsWriter do banco de dados “assets”:
use products db.runCommand( { revokeRolesFromUser: "productUser00", roles: [ { role: "AssetsWriter", db: "assets" }, "read" ], writeConcern: { w: "majority" } } )O usuário “productUser00” no banco de dados de produtos agora tem apenas uma função restante:

"roles" : [ { "role" : "readWrite", "db" : "stock" } ]Comandos de gerenciamento de função
As funções concedem aos usuários acesso aos recursos. Várias funções internas podem ser usadas por administradores para controlar o acesso a um sistema MongoDB. Se as funções não cobrirem os privilégios desejados, você pode ir além para criar novas funções em um banco de dados específico.
dropRole
Com o comando dropRole , você pode excluir uma função definida pelo usuário do banco de dados no qual executa o comando. Para executar este comando, use a seguinte sintaxe:
db.runCommand( { dropRole: "<role>", writeConcern: { <write concern> }, comment: <any> } ) Para uma execução bem-sucedida, você deve ter a ação dropRole no banco de dados especificado. As seguintes operações removeriam a função writeTags do banco de dados “produtos”:
use products db.runCommand( { dropRole: "writeTags", writeConcern: { w: "majority" } } )createRole
Você pode aproveitar o comando createRole para criar uma função e especificar seus privilégios. A função será aplicada ao banco de dados no qual você escolher executar o comando. O comando createRole retornaria um erro de função duplicada se a função já existir no banco de dados.
Para executar este comando, siga a sintaxe fornecida:
db.adminCommand( { createRole: "<new role>", privileges: [ { resource: { <resource> }, actions: [ "<action>", ... ] }, ], roles: [ { role: "<role>", db: "<database>" } | "<role>", ], authenticationRestrictions: [ { clientSource: ["<IP>" | "<CIDR range>", ...], serverAddress: ["<IP>" | "<CIDR range>", ...] }, ], writeConcern: <write concern document>, comment: <any> } )Os privilégios de uma função se aplicariam ao banco de dados em que a função foi criada. A função pode herdar privilégios de outras funções em seu banco de dados. Por exemplo, uma função feita no banco de dados “admin” pode incluir privilégios que se aplicam a um cluster ou a todos os bancos de dados. Ele também pode herdar privilégios de funções presentes em outros bancos de dados.
Para criar uma função em um banco de dados, você precisa ter duas coisas:
- A ação
grantRolenesse banco de dados para mencionar privilégios para a nova função, bem como para mencionar funções das quais herdar. - A ação
createRolenesse recurso de banco de dados.
O seguinte comando createRole criará uma função clusterAdmin no banco de dados do usuário:
db.adminCommand({ createRole: "clusterAdmin", privileges: [ { resource: { cluster: true }, actions: [ "addShard" ] }, { resource: { db: "config", collection: "" }, actions: [ "find", "remove" ] }, { resource: { db: "users", collection: "usersCollection" }, actions: [ "update", "insert" ] }, { resource: { db: "", collection: "" }, actions: [ "find" ] } ], roles: [ { role: "read", db: "user" } ], writeConcern: { w: "majority" , wtimeout: 5000 } })grantRolesToRole
Com o comando grantRolesToRole , você pode conceder funções a uma função definida pelo usuário. O comando grantRolesToRole afetaria as funções no banco de dados em que o comando é executado.
Este comando grantRolesToRole tem a seguinte sintaxe:
db.runCommand( { grantRolesToRole: "<role>", roles: [ { role: "<role>", db: "<database>" }, ], writeConcern: { <write concern> }, comment: <any> } ) Os privilégios de acesso são semelhantes ao comando grantRolesToUser — você precisa de uma ação grantRole em um banco de dados para a execução adequada do comando.
No exemplo a seguir, você pode usar o comando grantRolesToUser para atualizar a função productsReader no banco de dados “products” para herdar os privilégios da função productsWriter :
use products db.runCommand( { grantRolesToRole: "productsReader", roles: [ "productsWriter" ], writeConcern: { w: "majority" , wtimeout: 5000 } } )revokePrivilegesFromRole
Você pode usar revokePrivilegesFromRole para remover os privilégios especificados da função definida pelo usuário no banco de dados em que o comando é executado. Para uma execução adequada, você precisa manter a seguinte sintaxe em mente:
db.runCommand( { revokePrivilegesFromRole: "<role>", privileges: [ { resource: { <resource> }, actions: [ "<action>", ... ] }, ], writeConcern: <write concern document>, comment: <any> } )Para revogar um privilégio, o padrão “documento de recurso” deve corresponder ao campo “recurso” desse privilégio. O campo "ações" pode ser uma correspondência exata ou um subconjunto.
Por exemplo, considere a função manageRole no banco de dados de produtos com os seguintes privilégios que especificam o banco de dados “managers” como o recurso:
{ "resource" : { "db" : "managers", "collection" : "" }, "actions" : [ "insert", "remove" ] }Você não pode revogar as ações “inserir” ou “remover” de apenas uma coleção no banco de dados de gerenciadores. As seguintes operações não causam alteração na função:
use managers db.runCommand( { revokePrivilegesFromRole: "manageRole", privileges: [ { resource : { db : "managers", collection : "kiosks" }, actions : [ "insert", "remove" ] } ] } ) db.runCommand( { revokePrivilegesFromRole: "manageRole", privileges: [ { resource : { db : "managers", collection : "kiosks" }, actions : [ "insert" ] } ] } ) Para revogar as ações "inserir" e/ou "remover" da função manageRole , você precisa corresponder exatamente ao documento do recurso. Por exemplo, a seguinte operação revoga apenas a ação “remover” do privilégio existente:
use managers db.runCommand( { revokePrivilegesFromRole: "manageRole", privileges: [ { resource : { db : "managers", collection : "" }, actions : [ "remove" ] } ] } )A operação a seguir removerá vários privilégios da função “executiva” no banco de dados de gerentes:
use managers db.runCommand( { revokePrivilegesFromRole: "executive", privileges: [ { resource: { db: "managers", collection: "" }, actions: [ "insert", "remove", "find" ] }, { resource: { db: "managers", collection: "partners" }, actions: [ "update" ] } ], writeConcern: { w: "majority" } } )RolesInfo
O comando rolesInfo retornará informações de privilégio e herança para funções especificadas, incluindo funções internas e definidas pelo usuário. Você também pode aproveitar o comando rolesInfo para recuperar todas as funções com escopo para um banco de dados.
Para uma execução adequada, siga esta sintaxe:
db.runCommand( { rolesInfo: { role: <name>, db: <db> }, showPrivileges: <Boolean>, showBuiltinRoles: <Boolean>, comment: <any> } )Para retornar informações de uma função do banco de dados atual, você pode especificar seu nome da seguinte maneira:
{ rolesInfo: "<rolename>" }Para retornar informações de uma função de outro banco de dados, você pode mencionar a função com um documento que mencione a função e o banco de dados:
{ rolesInfo: { role: "<rolename>", db: "<database>" } }Por exemplo, o comando a seguir retorna as informações de herança de função para o executivo de função definido no banco de dados de gerentes:
db.runCommand( { rolesInfo: { role: "executive", db: "managers" } } ) Este próximo comando retornará as informações de herança de função: accountManager no banco de dados no qual o comando é executado:
db.runCommand( { rolesInfo: "accountManager" } )O comando a seguir retornará os privilégios e a herança de função para a função “executiva” conforme definido no banco de dados de gerentes:
db.runCommand( { rolesInfo: { role: "executive", db: "managers" }, showPrivileges: true } )Para mencionar várias funções, você pode usar uma matriz. Você também pode mencionar cada função na matriz como uma string ou documento.
Você deve usar uma string apenas se a função existir no banco de dados no qual o comando é executado:
{ rolesInfo: [ "<rolename>", { role: "<rolename>", db: "<database>" }, ] }Por exemplo, o comando a seguir retornará informações para três funções em três bancos de dados diferentes:
db.runCommand( { rolesInfo: [ { role: "executive", db: "managers" }, { role: "accounts", db: "departments" }, { role: "administrator", db: "products" } ] } )Você pode obter os privilégios e a herança de função da seguinte maneira:
db.runCommand( { rolesInfo: [ { role: "executive", db: "managers" }, { role: "accounts", db: "departments" }, { role: "administrator", db: "products" } ], showPrivileges: true } )Incorporando documentos do MongoDB para melhor desempenho
Bancos de dados de documentos como o MongoDB permitem que você defina seu esquema de acordo com suas necessidades. Para criar esquemas ideais no MongoDB, você pode aninhar os documentos. Portanto, em vez de corresponder seu aplicativo a um modelo de dados, você pode criar um modelo de dados que corresponda ao seu caso de uso.
Os documentos incorporados permitem armazenar dados relacionados que você acessa juntos. Ao projetar esquemas para o MongoDB, é recomendável incorporar documentos por padrão. Use junções e referências do lado do banco de dados ou do lado do aplicativo somente quando valerem a pena.
Certifique-se de que a carga de trabalho possa recuperar um documento com a frequência necessária. Ao mesmo tempo, o documento também deve conter todos os dados necessários. Isso é fundamental para o desempenho excepcional do seu aplicativo.
Abaixo, você encontrará alguns padrões diferentes para incorporar documentos:
Padrão de documento incorporado
Você pode usar isso para incorporar até mesmo subestruturas complicadas nos documentos com os quais elas são usadas. A incorporação de dados conectados em um único documento pode diminuir o número de operações de leitura necessárias para obter dados. Geralmente, você deve estruturar seu esquema para que seu aplicativo receba todas as informações necessárias em uma única operação de leitura. Portanto, a regra a ser lembrada aqui é que o que é usado em conjunto deve ser armazenado junto .
Padrão de subconjunto incorporado
O padrão de subconjunto incorporado é um caso híbrido. Você o usaria para uma coleção separada de uma longa lista de itens relacionados, onde você pode manter alguns desses itens à mão para exibição.
Aqui está um exemplo que lista resenhas de filmes:
> db.movie.findOne() { _id: 321475, title: "The Dark Knight" } > db.review.find({movie_id: 321475}) { _id: 264579, movie_id: 321475, stars: 4 text: "Amazing" } { _id: 375684, movie_id: 321475, stars:5, text: "Mindblowing" }Agora, imagine mil comentários semelhantes, mas você planeja exibir apenas os dois mais recentes quando exibir um filme. Nesse cenário, faz sentido armazenar esse subconjunto como uma lista no documento do filme:
> db.movie.findOne({_id: 321475}) { _id: 321475, title: "The Dark Knight", recent_reviews: [ {_id: 264579, stars: 4, text: "Amazing"}, {_id: 375684, stars: 5, text: "Mindblowing"} ] }</codeSimplificando, se você acessar rotineiramente um subconjunto de itens relacionados, certifique-se de incorporá-lo.
Acesso independente
Você pode querer armazenar subdocumentos em sua coleção para separá-los de sua coleção pai.
Por exemplo, pegue a linha de produtos de uma empresa. Se a empresa vende um pequeno conjunto de produtos, convém armazená-los no documento da empresa. Mas se você quiser reutilizá-los em todas as empresas ou acessá-los diretamente pela unidade de manutenção de estoque (SKU), também convém armazená-los em sua coleção.
Se você manipular ou acessar uma entidade de forma independente, faça uma coleção para armazená-la separadamente para melhor prática.
Listas ilimitadas
Armazenar listas curtas de informações relacionadas em seus documentos tem uma desvantagem. Se sua lista continuar crescendo sem controle, você não deve colocá-la em um único documento. Isso ocorre porque você não seria capaz de suportá-lo por muito tempo.
Há duas razões para isso. Primeiro, o MongoDB tem um limite no tamanho de um único documento. Segundo, se você acessar o documento em muitas frequências, verá resultados negativos do uso descontrolado da memória.
Simplificando, se uma lista começar a crescer sem limites, faça uma coleção para armazená-la separadamente.
Padrão de referência estendido
O padrão de referência estendido é como o padrão de subconjunto. It also optimizes information that you regularly access to store on the document.
Here, instead of a list, it's leveraged when a document refers to another that is present in the same collection. At the same time, it also stores some fields from that other document for ready access.
Por exemplo:
> db.movie.findOne({_id: 245434}) { _id: 245434, title: "Mission Impossible 4 - Ghost Protocol", studio_id: 924935, studio_name: "Paramount Pictures" }As you can see, “the studio_id” is stored so that you can look up more information on the studio that created the film. But the studio's name is also copied to this document for simplicity.
To embed information from modified documents regularly, remember to update documents where you've copied that information when it is modified. In other words, if you routinely access some fields from a referenced document, embed them.
How To Monitor MongoDB
You can use monitoring tools like Kinsta APM to debug long API calls, slow database queries, long external URL requests, to name a few. You can even leverage commands to improve database performance. You can also use them to inspect the ase/” data-mce-href=”https://kinsta.com/knowledgebase/wordpress-repair-database/”>health of your database instances.
Why Should You Monitor MongoDB Databases?
A key aspect of database administration planning is monitoring your cluster's performance and health. MongoDB Atlas handles the majority of administration efforts through its fault-tolerance/scaling abilities.
Despite that, users need to know how to track clusters. They should also know how to scale or tweak whatever they need before hitting a crisis.
By monitoring MongoDB databases, you can:
- Observe the utilization of resources.
- Understand the current capacity of your database.
- React and detect real-time issues to enhance your application stack.
- Observe the presence of performance issues and abnormal behavior.
- Align with your governance/data protection and service-level agreement (SLA) requirements.
Key Metrics To Monitor
While monitoring MongoDB, there are four key aspects you need to keep in mind:
1. MongoDB Hardware Metrics
Here are the primary metrics for monitoring hardware:
Normalized Process CPU
It's defined as the percentage of time spent by the CPU on application software maintaining the MongoDB process.
You can scale this to a range of 0-100% by dividing it by the number of CPU cores. It includes CPU leveraged by modules such as kernel and user.
High kernel CPU might show exhaustion of CPU via the operating system operations. But the user linked with MongoDB operations might be the root cause of CPU exhaustion.
Normalized System CPU
It's the percentage of time the CPU spent on system calls servicing this MongoDB process. You can scale it to a range of 0-100% by dividing it by the number of CPU cores. It also covers the CPU used by modules such as iowait, user, kernel, steal, etc.
User CPU or high kernel might show CPU exhaustion through MongoDB operations (software). High iowait might be linked to storage exhaustion causing CPU exhaustion.
Disk IOPS
Disk IOPS is the average consumed IO operations per second on MongoDB's disk partition.
Disk Latency
This is the disk partition's read and write disk latency in milliseconds in MongoDB. High values (>500ms) show that the storage layer might affect MongoDB's performance.
System Memory
Use the system memory to describe physical memory bytes used versus available free space.
The available metric approximates the number of bytes of system memory available. You can use this to execute new applications, without swapping.
Disk Space Free
This is defined as the total bytes of free disk space on MongoDB's disk partition. MongoDB Atlas provides auto-scaling capabilities based on this metric.
Swap Usage
You can leverage a swap usage graph to describe how much memory is being placed on the swap device. A high used metric in this graph shows that swap is being utilized. This shows that the memory is under-provisioned for the current workload.
MongoDB Cluster's Connection and Operation Metrics
Here are the main metrics for Operation and Connection Metrics:
Operation Execution Times
The average operation time (write and read operations) performed over the selected sample period.
Opcounters
It is the average rate of operations executed per second over the selected sample period. Opcounters graph/metric shows the operations breakdown of operation types and velocity for the instance.
Conexões
This metric refers to the number of open connections to the instance. High spikes or numbers might point to a suboptimal connection strategy either from the unresponsive server or the client side.
Query Targeting and Query Executors
This is the average rate per second over the selected sample period of scanned documents. For query executors, this is during query-plan evaluation and queries. Query targeting shows the ratio between the number of documents scanned and the number of documents returned.
Uma alta proporção numérica aponta para operações abaixo do ideal. Essas operações digitalizam muitos documentos para retornar uma parte menor.
Digitalizar e encomendar
Ele descreve a taxa média por segundo durante o período de amostra de consultas escolhido. Ele retorna resultados classificados que não podem executar a operação de classificação usando um índice.
Filas
As filas podem descrever o número de operações aguardando um bloqueio, seja de gravação ou leitura. As filas altas podem representar a existência de um design de esquema abaixo do ideal. Também pode indicar caminhos de escrita conflitantes, levando a uma alta competição pelos recursos do banco de dados.
Métricas de replicação do MongoDB
Aqui estão as principais métricas para monitoramento de replicação:
Janela de Oplog de Replicação
Essa métrica lista o número aproximado de horas disponíveis no oplog de replicação do primário. Se um secundário atrasar mais do que esse valor, ele não poderá acompanhar e precisará de uma ressincronização completa.
Atraso de replicação
O atraso de replicação é definido como o número aproximado de segundos que um nó secundário está atrás do primário nas operações de gravação. O atraso de replicação alto apontaria para um secundário que enfrenta dificuldades na replicação. Isso pode afetar a latência da sua operação, devido à preocupação de leitura/gravação das conexões.
Espaço de replicação
Essa métrica se refere à diferença entre a janela de oplog da replicação primária e o atraso de replicação da secundária. Se este valor for zero, pode fazer com que um secundário entre no modo RECOVERING.
Opcounters -repl
Opcounters -repl é definido como a taxa média de operações de replicação executadas por segundo para o período de amostra escolhido. Com o opcounters -graph/metric, você pode dar uma olhada na velocidade das operações e detalhamento dos tipos de operação para a instância especificada.
oplog GB/hora
Isso é definido como a taxa média de gigabytes de oplog que o primário gera por hora. Altos volumes inesperados de oplog podem apontar para uma carga de trabalho de gravação altamente insuficiente ou um problema de design de esquema.
Ferramentas de monitoramento de desempenho do MongoDB
O MongoDB possui ferramentas de interface de usuário integradas no Cloud Manager, Atlas e Ops Manager para rastreamento de desempenho. Ele também fornece alguns comandos e ferramentas independentes para examinar mais dados brutos. Falaremos sobre algumas ferramentas que você pode executar a partir de um host que tenha acesso e funções apropriadas para verificar seu ambiente:
mongotop
Você pode aproveitar esse comando para rastrear a quantidade de tempo que uma instância do MongoDB gasta gravando e lendo dados por coleção. Use a seguinte sintaxe:
mongotop <options> <connection-string> <polling-interval in seconds>rs.status()
Este comando retorna o status do conjunto de réplicas. É executado do ponto de vista do membro onde o método é executado.
mongostato
Você pode usar o comando mongostat para obter uma visão geral rápida do status da sua instância do servidor MongoDB. Para uma saída ideal, você pode usá-lo para observar uma única instância de um evento específico, pois oferece uma visualização em tempo real.
Aproveite este comando para monitorar estatísticas básicas do servidor, como filas de bloqueio, quebra de operação, estatísticas de memória do MongoDB e conexões/rede:
mongostat <options> <connection-string> <polling interval in seconds>dbStats
Este comando retorna estatísticas de armazenamento para um banco de dados específico, como o número de índices e seu tamanho, dados de coleta total versus tamanho de armazenamento e estatísticas relacionadas à coleção (número de coleções e documentos).
db.serverStatus()
Você pode aproveitar o comando db.serverStatus() para ter uma visão geral do estado do banco de dados. Ele fornece um documento que representa os contadores de métrica da instância atual. Execute este comando em intervalos regulares para reunir estatísticas sobre a instância.
colStats
O comando collStats coleta estatísticas semelhantes às oferecidas pelo dbStats no nível de coleta. Sua saída consiste em uma contagem de objetos na coleção, a quantidade de espaço em disco consumido pela coleção, o tamanho da coleção e informações sobre seus índices para uma determinada coleção.
Você pode usar todos esses comandos para oferecer relatórios e monitoramento em tempo real do servidor de banco de dados que permite monitorar o desempenho e os erros do banco de dados e auxiliar na tomada de decisões informadas para refinar um banco de dados.
Como excluir um banco de dados MongoDB
Para descartar um banco de dados que você criou no MongoDB, você precisa se conectar a ele por meio da palavra-chave use.
Digamos que você criou um banco de dados chamado “Engenheiros”. Para se conectar ao banco de dados, você usará o seguinte comando:
use Engineers Em seguida, digite db.dropDatabase() para se livrar desse banco de dados. Após a execução, este é o resultado que você pode esperar:
{ "dropped" : "Engineers", "ok" : 1 } Você pode executar o comando showdbs para verificar se o banco de dados ainda existe.
Resumo
Para extrair cada gota de valor do MongoDB, você deve ter uma forte compreensão dos fundamentos. Portanto, é fundamental conhecer os bancos de dados MongoDB como a palma da sua mão. Isso requer familiarizar-se com os métodos para criar um banco de dados primeiro.
Neste artigo, esclarecemos os diferentes métodos que você pode usar para criar um banco de dados no MongoDB, seguido por uma descrição detalhada de alguns comandos bacanas do MongoDB para mantê-lo atualizado sobre seus bancos de dados. Por fim, encerramos a discussão discutindo como você pode aproveitar documentos incorporados e ferramentas de monitoramento de desempenho no MongoDB para garantir que seu fluxo de trabalho funcione com eficiência máxima.
Qual é a sua opinião sobre esses comandos do MongoDB? Perdemos um aspecto ou método que você gostaria de ver aqui? Deixe-nos saber nos comentários!